StackOverflow sees quite a few threads deleted, usually for good reasons. Among the stinkers, though, lies the occasionally useful or otherwise interesting one, deleted by some pedantic nitpicker - so I resurrect them. 👻
Note: Because these threads are older, info may be outdated and links may be dead. Feel free to contact me, but I may not update them... this is an archive after all.
It seems like there are so many subfields linked to Machine Learning. Is there a book or a blog that gives an overview of those different fields and what each of them do, maybe how to get started, and what background knowledge is required?
It's laughable how many good, useful questions are closed on SO. This question has 155 upvotes and 234 stars at the time of this writing, and the accepted answer has 153 upvotes.
– weberc2Oct 9 '14 at 20:25
Once you've played around a bit, watch Ben Hamner's "Machine Learning Gremlins" for a nice pragmatic disclaimer of what can easily go wrong when doing machine learning.
I wrote a blog post "Computing Your Skill" after spending months trying to understand TrueSkill, the ML system that does matchmaking and ranking on Xbox Live. The post goes into some foundational statistics needed for further study in machine learning.
Perhaps the best way to learn is to just try it. One approach is to try a Kaggle competition that sounds interesting to you. Even though I don't do great on the leaderboards there, I always learn things when I try a competition.
After that you've done the above, I'd then recommend something more formal like Andrew Ng's online class. It's at the college level, but approachable. If you've done all the above steps, you'll be more motivated to not give up when you hit some harder things.
You are right to feel that there are lots of sub-fields to ML.
Machine Learning in general is basically just the idea of Algorithms which improve over time. If you're simply curious, some random topics that come to mind include:
Classification, Association analysis, Clustering, Decision Trees, Genetic Algorithms, Concept Learning
As far as books go:
I'm currently using Introduction to Data Mining for a course right now. It covers quite a few of the topics I've listed above and usually has examples of algorithms/uses in each section.
You don't need too much background knowledge to understand a lot of the topics. Most algorithms have some math underlying them which is used to improve the results, and you obviously need to be comfortable with general programming/data structures.
I've been using 'Machine Learning: An algorithmic Perspective' by Stephen Marsland. And I think the approach is awesome. The author has put up the python code on his site. So you can actually download the code and look at it just to take a peek at how things work.
Shared with attribution, where reasonably possible, per the SO attribution policy and cc-by-something. If you were the author of something I posted here, and want that portion removed, just let me know.
I was checking the status of a FedEx order in Brave, when I noticed a notification in the address bar that I've never seen before. It was warning me that "this site has been blocked from accessing your motion sensors". Wut? It doesn't even need to be an order status - their home page kicks it up too.
I'm struggling to understand why a website would need access to a motion sensor on a mobile device, let alone the fact I was using a desktop. Do I get a different experience if I knock my PC off the desk? Tip my monitor on its side? Grab the mouse cord and spin it around my head really fast?
After a few cursory online searches, I'm coming up with little other than a few threads on Reddit and Brave that indicate people are also seeing this on Kayo Sports and Twitch, as well as Experian and Tutanota.
Guess it's time to dig a little deeper.
What are Web APIs?
Before zeroing in on sensors, let's backup a sec and talk about web design and Web APIs. Your browser has access to a lot of data via (and metadata regarding) the device you installed it on. As much as some of the websites you visit would looove to have access to all that data, any decent browser acts as a firewall, blocking that access by default and prompting you to allow it.
Geolocation API
One of the more common APIs is the one used to request your location, usually when you're using a websites's "store locator" to find the store nearest you.
Your browser prompts you to allow access, which you can deny. Yay privacy.
If you don't see the prompt but you think you've allowed it, there are two different settings that control access - a global page with a list of "blocked" and "allowed" sites, and a per-site page where you can adjust all permissions for a single site. In Chrome, just replace brave:// with chrome:// in the address bar.
Notifications API
Another (unfortunately, very) popular API is the one used to display notifications to visitors. Using the Notifications API, you can request permission from a visitor with a call to Notification.requestPermission() and then just create a new Notification() to annoy them keep them up to date. (May not work in Brave due to a bug.)
Sensors API
There's a (maybe sorta?) new API for requesting access to sensors in Chromium-based browsers (Ghacks puts it at Chrome 75, around June 2019, but wikipedia suggests Chrome 67 around May 2018). It's not widely supported yet. According to MDN, the only major browsers that currently support it are Chrome and Opera, on desktop and mobile.
The following links execute some JavaScript code to try starting up various sensors, which should trigger the sensor icon in the address bar. (If an error occurs, it'll display below the links.)
As with the geolocation and notification APIs, you can grant or deny access at the global or per-site level. What's kind of annoying is that all of the above sensors fall under a single "motion sensors" umbrella, so you can't easily tell which of those sensors a particular site is trying to access.
Why are certain sites requesting the Sensors API?
That's the hundred-dollar question. I see it on FedEx and Kayo Sports (every time) and Twitch (sometimes). I'm sure there's other sites too, but the question is, why do sites as varied as these want access to a gyroscope or accelerometer?
I haven't confirmed anything, but if I had to guess, I'd say they're all using the same library, and it got changed. Like all modern development, websites are built upon layers and layers of libraries that depend on other libraries. Somewhere down the line, I wonder if one is requesting access to an API that it doesn't need? After poking around a bit, I didn't see anything obvious, but then some of the scripts were obfuscated so there's little chance of figuring those out.
Your guess is as good as mine, but like all the Web APIs, if you don't believe a site needs the data it's requesting access to, tell your browser to block it!
If you've ever needed to consume a webhook from another service, say from Stripe or GitHub, but you weren't completely sure what the payload was going to look like (say, the docs are incomplete or missing), a tool like RequestBin can help. By setting it as the "target" for the webhook, it intercepts whatever happens to be thrown its way, and displays it.
Same goes if you're developing a REST API and want to make sure that your POST and PUT actions are sending what you expect. You could develop a separate app that consumes your API the way your customers will and displays the results, but why bother with the overhead? (At least, initially...)
The same team that designed RequestBin (which seems to be abandoned, but more on that below) used to host a public instance of it for anyone to use too, but such services don't seem to last, and theirs didn't either once the VC money dried up. It's got to be expensive hosting something like that for thousands (tens of thousands? hundreds?) of users for free. 💸
Deploy with DigitalOcean in <5 minutes
Fortunately, the makers of RequestBin also made it really easy to deploy on your own. Just create a DigitalOcean droplet with Docker preinstalled; unless you know you're going to need more resources, the basic $5/mo plan is sufficient. It should only take a minute or so to spin up.
Connect to your new VM, most likely with ssh root@<your-droplet-ip-address>, and then run the commands in the readme. The build command takes a few minutes on its own, but the up command should only take a few seconds.
git clone git://github.com/Runscope/requestbin.git
cd requestbin
sudo docker-compose build
sudo docker-compose up -d
Assuming no errors in the output, just paste <your-droplet-ip-address>:8000 into your favorite browser, and away you go!
Create your first RequestBin and POST some data with a simple curl command like they suggest. Update the page and you should see your data listed.
You can also use a tool like Postman to make requests to the endpoint, and even save them for future use - something I've made extensive use of while learning and writing about various APIs.
Changing Built-in Settings (i.e. max TTL, max requests, and port)
There's some settings, like a max of 20 requests, that make sense if you've got an environment that thousands of people will be using. But since it's just you, and maybe a small team, I'd say you could safely increase those a bit.
If the container is up and running, bring it down now and verify it's gone.
root@docker-s-1vcpu-1gb-nyc3-01:~# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0f9ecfdde471 requestbin_app "/bin/sh -c 'gunicor…" 25 minutes ago Up 25 minutes 0.0.0.0:8000->8000/tcp requestbin_app_1
99415b11ab7c redis "docker-entrypoint.s…" 25 minutes ago Up 25 minutes 6379/tcp requestbin_redis_1
root@docker-s-1vcpu-1gb-nyc3-01:~# cd ~/requestbin/
root@docker-s-1vcpu-1gb-nyc3-01:~/requestbin# sudo docker-compose down
Stopping requestbin_app_1 ... done
Stopping requestbin_redis_1 ... done
Removing requestbin_app_1 ... done
Removing requestbin_redis_1 ... done
root@docker-s-1vcpu-1gb-nyc3-01:~/requestbin# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Open the requestbin/config.py file and change some of these values.
The BIN_TTL is the time to live in seconds, so if you want your requests to live for a year, then set BIN_TTL = 365*24*3600
There's no reason to only hold on to 20 requests; if you like, you could set MAX_REQUESTS = 2000 or some other value. If you set it to a million and everything crashes... not my fault.
While you're at it, you could make it so you don't have to enter a port either, since presumably you're not running anything else on this tiny server.
Edit docker-compose.yml and change the "ports" section to "80:8000"
Edit Dockerfile to EXPOSE 80
Remove the current requestbin_app image with docker image rm
Run sudo docker-compose up -d again and verify your changes took effect
Some of the values are also hard-coded into the HTML page, so even after doing all the above, the page will probably still tell you you're limited to 20 requests. It lies. If you run the CURL command 30 times now, you'll see 30 requests on the page.
Other Considerations
So, hopefully you haven't been passing anything too sensitive to your RequestBin instance yet, because right now it's all plain-text. If you need to pass secure data, consider setting up SSL. That's not something I'm delving into here - not yet, anyway.
I forked the original project which, as I mentioned, seems to be abandoned. They shutdown the public RequestBin site (understandably), but also haven't merged in PRs or addressed issues for nearly two years.
Small side note: If you go into "Insights", "Dependency Graph", and click "Enable", GitHub warns you of security vulnerabilities (even on a fork)... and then opens PRs on your behalf, which you can merge in or close at your discretion! 👍
I'd love to update the dependencies (i.e. Python2 is dead), merge the pending PRs, and even try addressing some of the issues myself, but that's probably a fool's errand... at least for this fool. It's a complex project, and if I'm honest, I don't have the time to dedicate to properly understanding it and bringing it up to speed.
I've heard it said that a business's purpose, reduced to a single point, is to separate you from your money. A little cynical, sure... but not wrong. A company might appeal to your compassion, outrage, or sensibilities, prey on your doubts and fears, win you over with clever marketing, or just scratch an itch you didn't even know you had. Some do a nice job of reinvesting in their employees and community. But at the end of the day, it's (ultimately) about keeping the lights on.
It's hard enough to see past our own feelings, to judge a product on its own objective merits, but at least when we buy into something, we can usually just as easily stop buying into it. Sure, there's contracts and whatnot, but when you don't renew, the problem is solved.
But these days, the hot commodity isn't the green stuff in your wallet. The modern business's purpose, reduced to a single point, seems to be to separate you from your data.And as it happens, I stumbled across several instances of data mining wrapped up as "features" just last week.
LinkedIn cares about your team
After I accepted a connection from a legit coworker, LinkedIn asked if they were a current or past coworker. Odd.. surely they could determine that from our mutual "experience" sections.
Ah, they've got a "teammates" feature, and they want to start the ball rolling on my filling in details about working relationships. And while I'm at it, I could pony up details about my other connections too. This is all for my convenience of course - never miss an important update!
Perceived Benefit: By telling LinkedIn who your current and past manager, direct reports, and team members were/are, you'll be fed more relevant updates and stories in your timeline. If you do (or did) work for a corporation with thousands of employees, then having the same company listed on both your profiles doesn't necessarily mean you want to know everything about that person, so you can feed their algorithm and get the more relevant (to you) stuff.
Data Opportunity: LinkedIn already knows who works (or did work) for the same company, but this gives them access to something they don't have - your corporate structure. If enough people feed the machine info about who they work with and in what capacity, it's easily possible for LinkedIn to piece together a company's internal structure.
Potential Risk: Many companies publicize their top leadership, but not many list everyone. And few to none would make their complete org chart public, but that's exactly what LinkedIn would have. Is that considered sensitive info? I'm not sure. It seems like the kind of thing most companies would like to remain confidential.
Facebook cares about your health
Have you heard about Facebook's new Preventive Health portal? Hand over your medical information to FB, and they'll make recommendations on what kinds of other preventive measures you should take.
Perceived Benefit: Facebook will show you recommendations for preventive health, based on your age and gender. If you let them know what medical checkups you've already completed over the years, they'll make it more personalized.
Data Opportunity: Facebook gets access to your medical data. I can't imagine what kind of new and amazing ads they can start targeting you with once they realize the kinds of medical treatments you're having done, or are scheduled to do. They say, "we're starting with health checkups related to heart disease, cancer and flu", so if this is remotely successful, it'll almost certainly extend to all kinds of medical issues.
Not to mention, "at this time, Preventive Health is only available on the Facebook mobile app", for reasons I can't even guess. All the mobile app requests access to is your contacts, calendar, phone log, app history, microphone, camera, location, media, sms, so... seems legit.
Potential Risk: In the US, "The HIPAA Privacy regulations require health care providers and organizations, as well as their business associates, to develop and follow procedures that ensure the confidentiality and security of protected health information (PHI) when it is transferred, received, handled, or shared."
But in Facebook's own words:
Facebook doesn't endorse any particular health care provider.
Locations don’t pay Facebook to be included on maps in Preventive Health.
Neither Facebook, nor any of its products, services or activities are endorsed by CDC or the U.S. Government.
Facebook isn't a health care provider, nor a health care provider's business associate, so no HIPAA. Besides, given their abysmal record on data breaches, I'd be wary of any promises they made anyway.
Amazon cares about your privacy
And someone on Twitter posted this warning they got when visiting Amazon.com with the Honey browser extension installed. It's an extension that monitors what you're shopping for, and lets you know if it's cheaper somewhere else or there's coupons. I installed Honey to try replicating it, but couldn't.
Perceived Benefit: Amazon is issuing a public service announcement, trying to protect you (their loyal customer) from the harms of a rogue browser extension.
Data Opportunity: Amazon has their own browser extension, which has far fewer ratings and an lower overall rating, and which (according to the permissions it requests) can access the sites you visit, access your bookmarks and location, manage your other extensions, observe and analyze network traffic and intercept, block, or modify that traffic, similar too (but more extensive than) the Honey extension.
Potential Risk: If all you do is uninstall Honey, there's not really any risk. If you replace it with Amazon's extension, I'd say you're giving up even more data, feeding the giant machine. They promise to help you "price compare across the web", but that's a difficult pill to swallow. Besides, it's a little tough to buy the "security risk" bit from a company that wants to install listening devices into your home, sometimes with unexpected, shady results.
As a side note, I don't even know how Amazon managed to detect that Honey was installed. I can think of two possibilities. First, maybe the twitter poster had the Amazon extension installed too. With the "management" permission, it might be able to detect Honey by itself. I tried it, but I didn't get a warning.
The other possibility is that they're running a bit of javascript code client-side, sometime after the page loads, that detects Honey. Sites do stuff like that with ad blockers frequently, and it's fairly trivial.
For example, I uploaded a small file called "ads.js" to my site (view it here), which is basically guaranteed to be blocked by ad blockers. Then below, on this post only, I attempt to load the script and run a second script that detects whether the variable in that file was created. If it wasn't, then your ad blocker blocked the "ads.js" script. Try disabling your ad blocker and refresh the page, and the message below should change.
No Adblocker!
Since Honey probably injects something into the page to help users get the best deal, Amazon could inject some code into their page that inspects the DOM for some element that they know Honey creates, and then display a warning at the top.
Conflict of interest, anyone?
There's so much caring going on, I'm getting weepy
I could go on and on with other examples, but the moral of the story is that when a company rolls out a new "feature" that exchanges your personal data - especially something they wouldn't otherwise have access to - in exchange for a little convenience, take a second or two to think about what they stand to profit from it.
Once that data is in their hands, you can't do much about it, and they may be able to profit from it any way they like for a long time.
Ever gone looking for the end of the Internet? It's not hard to find.. turns out there's dozens of ends. Which makes sense really, since the web is by definition nonlinear.. it's more of a mish-meshy, hydra sorta thing that's forever expanding. To make your very own "end" though, just create a page with absolutely no outgoing links. Ta-da.
Beginnings
A better trick is finding the beginning of the Internet. Well.. it's still there!
Over the years, servers moved around, systems were reformatted, files were lost... history became legend, legend became myth and for two and a half decades, the first page passed out of all knowledge until, when chance came in 2013, it was rehosted at its original domain. But probably not on Tim Berners-Lee's original NeXT machine. 😏
Check it out, in all its simplified simplicity, including a list of people at CERN who were developing the WorldWideWeb project, some help docs, a list of other servers connected to this early "web", etc. I can't believe they hung on to them.. I can't even find my first website, and I know I saved it somewhere...
It's.. quaint, how few servers there were in the beginning. Most of them seem to be lost forever, but the Internet Archive crawled some before they disappeared, such as:
There were also attempts, pre modern search engines obviously, to manually index the entirety of the web. One attempt was Netscape's Open Directory Project, whose goal was to "produce the most comprehensive directory of the web by relying on a vast army of volunteer editors".
Good Intentions
It strikes me, looking at that list of servers, that the beginning of the web was full of good intentions. Scientists, engineers, professors.. universities, science labs... the WorldWideWeb project was supposed to be bring together all kinds of centers of learning.
I had (and still have) a dream that the web could be less of a television channel and more of an interactive sea of shared knowledge. I imagine it immersing us as a warm, friendly environment made of the things we and our friends have seen, heard, believe or have figured out.
I would like it to bring our friends and colleagues closer, in that by working on this knowledge together we can come to better understandings. If misunderstandings are the cause of many of the world's woes, then can we not work them out in cyberspace. And, having worked them out, we leave for those who follow a trail of our reasoning and assumptions for them to adopt, or correct.
Unfortunately, it's far outgrown that early vision, morphing into something that at times is vitriolic and ugly, used for exploitation or maliciousness. Don't blame the tool - it was as inevitable as the human spirit. How people use it reflects what's already in their hearts, and there's a lot of good on the web too.
For about a year after the first website was made available again in 2013, there was a pretty concerted effort to restore and maintain archives of a lot of software and hardware related to the same timeframe, which you can read about here.
Every time I learn some new piece of CSS I'm amazed at how flexible and powerful it is, and the prefers-color-scheme media element is no exception. The "dark mode" setting from a visitor's desktop or mobile device can be passed to the browser, which then applies it to your site according to your style sheets. So. Cool.
MDN has a good example and lots of notes, as usual (I love their docs!), and I created my own fun little example below. To try it out, toggle between light and dark mode on your device, and the sun should change to a moon. If it doesn't work for some reason, you can see what it should do in the screen capture at the bottom of this post. 🌞 🌜
How's it work?
Without diving too deep, here's a few pieces to the puzzle...
Responsive Design
It's possible (and has been for years) to design a website that responds to the device a visitor happens to be using, such as the wildly different screen sizes between a mobile device vs a desktop. This could involve writing JavaScript, but as CSS is given more power, it's able to handle most layouts all by itself.
Media Queries
One element of CSS that figures into responsive design is the media query, which can account for things like screen resolution, orientation, and whether the visitor prefers higher contrast colors.
For this to work, a device has to make this data available to the browser, which in turn has to use it to apply the correct CSS layout to the page. Different layouts result in different color schemes, collapsed menus, sidebars dropping below the post, etc.
Prefers-color-scheme Feature
One of the media features, called prefers-color-scheme, is used to determine whether the user prefers light mode or dark mode. It's based on their device settings, and most browsers support it.
You specify your "base" styles first - whatever you want applied no matter the device setting - and then you can override those based on whether the visitor prefers light or dark mode. Here's the code I used for the images above:
Notice that there's a setting for when they haven't indicated a preference, and I used the , to indicate an "or" clause, meaning (in my example) that the sun image and skyblue background will show up if they've selected "light" mode or nothing at all.
And just in case it doesn't work for you, which probably means you're either using an unsupported browser or your device doesn't pass those settings to the browser, this is how it looks in Windows when I toggle between modes. In clockwise order is DuckDuckGo who has a whole separate theme, the MDN example I loved so much, the Windows settings for dark mode, aaaand.. some new-agey sun/moon example someone put together.
If you already know why you're here, then just plug the public URL (or the calendar ID) from the calendar settings page, and click the appropriate button to get the iCal link. For everyone else, scroll past the text boxes for a brief explanation...
Public URL:
Calendar ID:
Converted:Copied!
I got my calendar, now learn me more!
Impressive, you didn't just run off. This won't take too long, I promise.
When someone creates a public Google calendar and shows it off to the world, you'll usually see a little "+ Google Calendar" button in the lower-right corner. Click on that, and you can import the calendar into your own Google account! How exciting!!
Unless you've replaced it with another service, like I did. 😐
Shockingly, you might not want to import a Google calendar into a Google account. So you might double-check the calendar settings, and see a "Public URL". And you might think you can import that into another client. You might be very wrong.
The reason it can't be imported is that the Public URL from Google is really just a link to an HTML page, and other clients don't know what the heck to do with it. You need something that's standardized, that all clients can easily consume and do something with. You need an iCalendar file, which (if you open it up in a text editor) looks something like this:
BEGIN:VCALENDAR
PRODID:-//Google Inc//Google Calendar 70.9054//EN
VERSION:2.0
CALSCALE:GREGORIAN
METHOD:PUBLISH
X-WR-TIMEZONE:UTC
BEGIN:VEVENT
DTSTART;VALUE=DATE:20210402
DTEND;VALUE=DATE:20210403
DTSTAMP:20200227T163343Z
UID:20210402_60o30dr5coo30c1g60o30dr56k@google.com
CLASS:PUBLIC
CREATED:20190517T221201Z
DESCRIPTION:Holiday or observance in: Connecticut\, Hawaii\, Delaware\, Ind
iana\, Kentucky\, Louisiana\, New Jersey\, North Carolina\, North Dakota\,
Tennessee\, Texas
LAST-MODIFIED:20190517T221201Z
SEQUENCE:0
STATUS:CONFIRMED
SUMMARY:Good Friday (regional holiday)
TRANSP:TRANSPARENT
END:VEVENT
BEGIN:VEVENT
DTSTART;VALUE=DATE:20200410
DTEND;VALUE=DATE:20200411
DTSTAMP:20200227T163343Z
UID:20200410_60o30dr5coo30c1g60o30dr56g@google.com
CLASS:PUBLIC
CREATED:20190517T221201Z
DESCRIPTION:Holiday or observance in: Connecticut\, Hawaii\, Delaware\, Ind
iana\, Kentucky\, Louisiana\, New Jersey\, North Carolina\, North Dakota\,
Tennessee\, Texas
LAST-MODIFIED:20190517T221201Z
SEQUENCE:0
STATUS:CONFIRMED
SUMMARY:Good Friday (regional holiday)
TRANSP:TRANSPARENT
END:VEVENT
...
...
BEGIN:VEVENT
DTSTART;VALUE=DATE:20191224
DTEND;VALUE=DATE:20191225
DTSTAMP:20200227T163343Z
UID:20191224_60o30dr56ko30c1g60o30dr56c@google.com
CLASS:PUBLIC
CREATED:20140108T163258Z
DESCRIPTION:
LAST-MODIFIED:20140108T163258Z
SEQUENCE:0
STATUS:CONFIRMED
SUMMARY:Christmas Eve
TRANSP:TRANSPARENT
END:VEVENT
BEGIN:VEVENT
DTSTART;VALUE=DATE:20191102
DTEND;VALUE=DATE:20191103
DTSTAMP:20200227T163343Z
UID:20191102_60o30c9g6ko30c1g60o30dr56c@google.com
CLASS:PUBLIC
CREATED:20140108T163258Z
DESCRIPTION:
LAST-MODIFIED:20140108T163258Z
SEQUENCE:0
STATUS:CONFIRMED
SUMMARY:All Souls' Day
TRANSP:TRANSPARENT
END:VEVENT
END:VCALENDAR
Predictable, no?
As luck would have it, even though they don't make it obvious, you can easily extract the Calendar ID from any Google calendar URL (or just use the calendar ID directly if you know it), and replace {CALENDAR_ID} in the following URL. Or use the script I wrote, above.
Whenever you visit a web page, your browser includes some basic info about your environment in the request, like your IP address, screen resolution, the page you're requesting (duh), the page you came from, etc. You can see it in action here or here. Individual websites can log that information to see which pages (or posts in the case of bloggers) are the most popular over time, which sites are linking to their site, etc. It's pretty useful stuff.
Feeding the Machine
Well, the IP address part is a little creepy. It's an easy way to track someone doing something shady (if they're not using a VPN), but it's also an easy way for an advertiser to track you across the web. Wait, how's that possible? It's not like advertisers have access to all those servers. I can login to my server and view logs about visitors, but advertisers can't. Enter Google Analytics.
Just plug Google's code into the header of every page on your site, and you get access to things you already had access to, along with questionable stuff like demographics (gender, age, etc). But how?
That code sends all your private visitor data to Google, who slurps it up, feeds it to their big data monster, combines it with all the data coming from millions of other sites running the same code, along with cookies and identifiers, their DoubleClick tracker, etc, and presents a bunch of stats to you.
Like I said, advertisers couldn't have access to all that data unless you voluntarily sent it to them. In essence, you're trading your visitor's privacy for some stats that you might not even need or understand, but Google absolutely understands it all, and happily uses it to help advertisers serve up ads across the web. You can read more about where demographics and interests data comes from as well as a tracking code overview, straight from the horse's mouth.
Starving the Machine
There's another way. For the vast majority of bloggers and small website owners, the data you're interested in is already at your fingertips. Do you really need Google to tell you whether your content is being consumed by men, women, kids, or any other particular group? Do you even care, as long as someone finds it useful?
Personally, I'm only interested in which pages are most popular (so I can invest my time wisely in updating posts), who's referring visitors to my site (it might indicate a site where I should engage more), and how many total visitors I'm getting (if I choose to display an ad for some service I think is useful, it might be helpful to tell them I get xx number of visitors per month). Aaaaand.. that's about it. I don't care about your IP address or anything else.
There's a number of services that are more privacy-minded than Google Analytics, though admittedly that particular bar is pretty low. Just to name a few, Simple Analytics starts at $10/mo, Matomo is $20/mo or free to self-host, and GoAccess is a free self-hosted solution too. Another one is Fathom, which is $12/mo or free to self-host.
Replacing the Machine
I looked at a few, and ultimately settled on Fathom. The interface is clean, they don't use cookies to track visitors, and they even respect the "Do Not Track" setting in your browser. First though, I gotta say that one of my favorite features on DigitalOcean is the ability to take a snapshot of a server before making a change, and if installing some piece of software goes horribly wrong, a restore is only one click away. 😅
The instructions for installing Fathom are pretty straight-forward. If you want to deploy a brand new instance, try out DigitalOcean's Fathom Analytics droplet. Since I'm running this site on an pre-existing Ubuntu server that's already running Ghost, I had to take some extra steps. I'll toss them out here - whether or not they're helpful depends on your setup.
I selected the latest "fathom_1.2.1_linux_amd64.tar.gz" release.
I followed the "Configuring Fathom" section - even though it says it's optional, it seems to be required in the section for setting up an admin user.
I already had SSL configured for my blog, so I created an /etc/nginx/sites-enabled/my-fathom-site.conf file and copied the details from my blog's SSL file. After a few changes, I can now use the same Let's Encrypt certificate for my blog and the Fathom dashboard.
I configured UFW to allow the secure port for the dashboard.
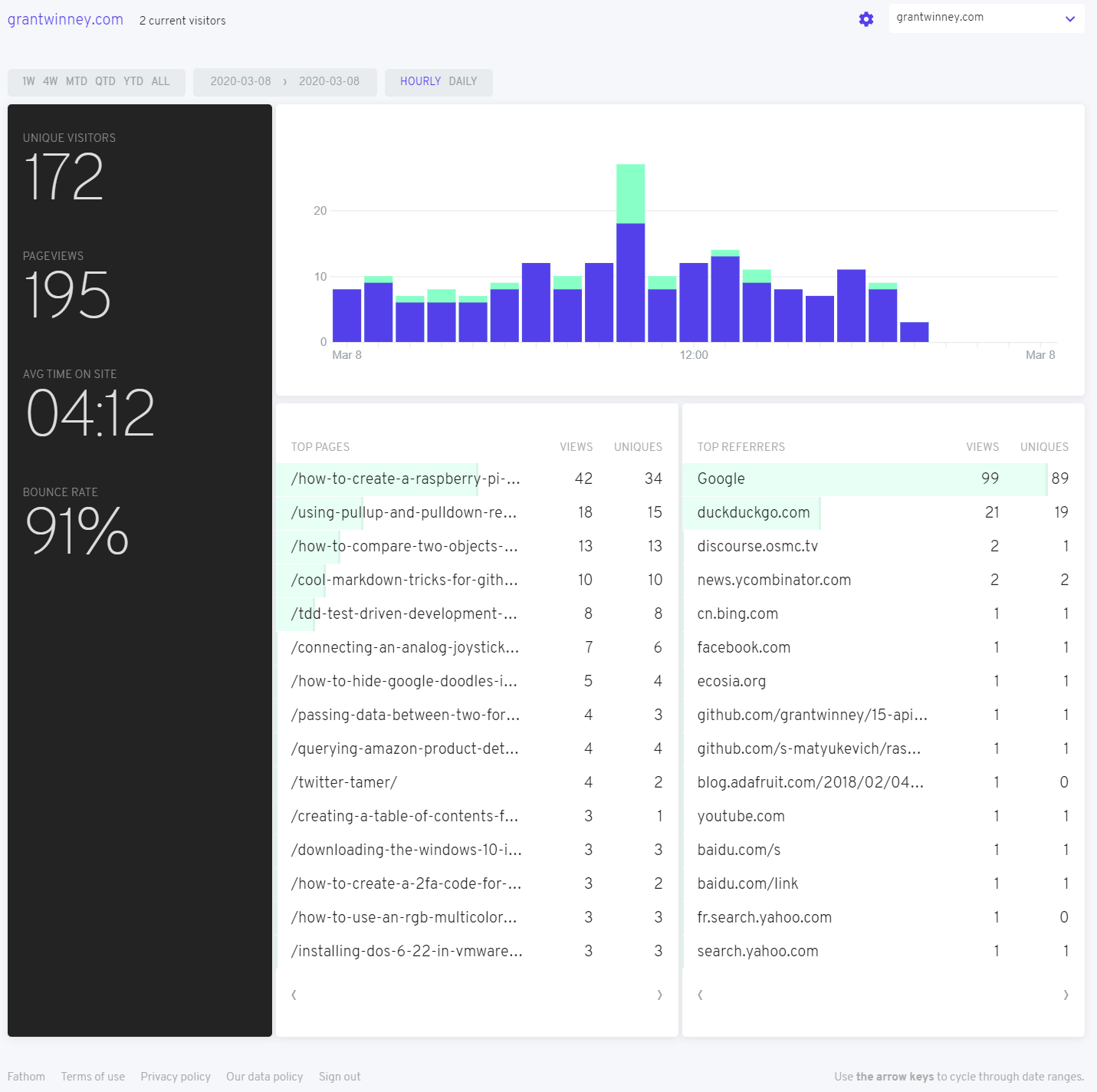
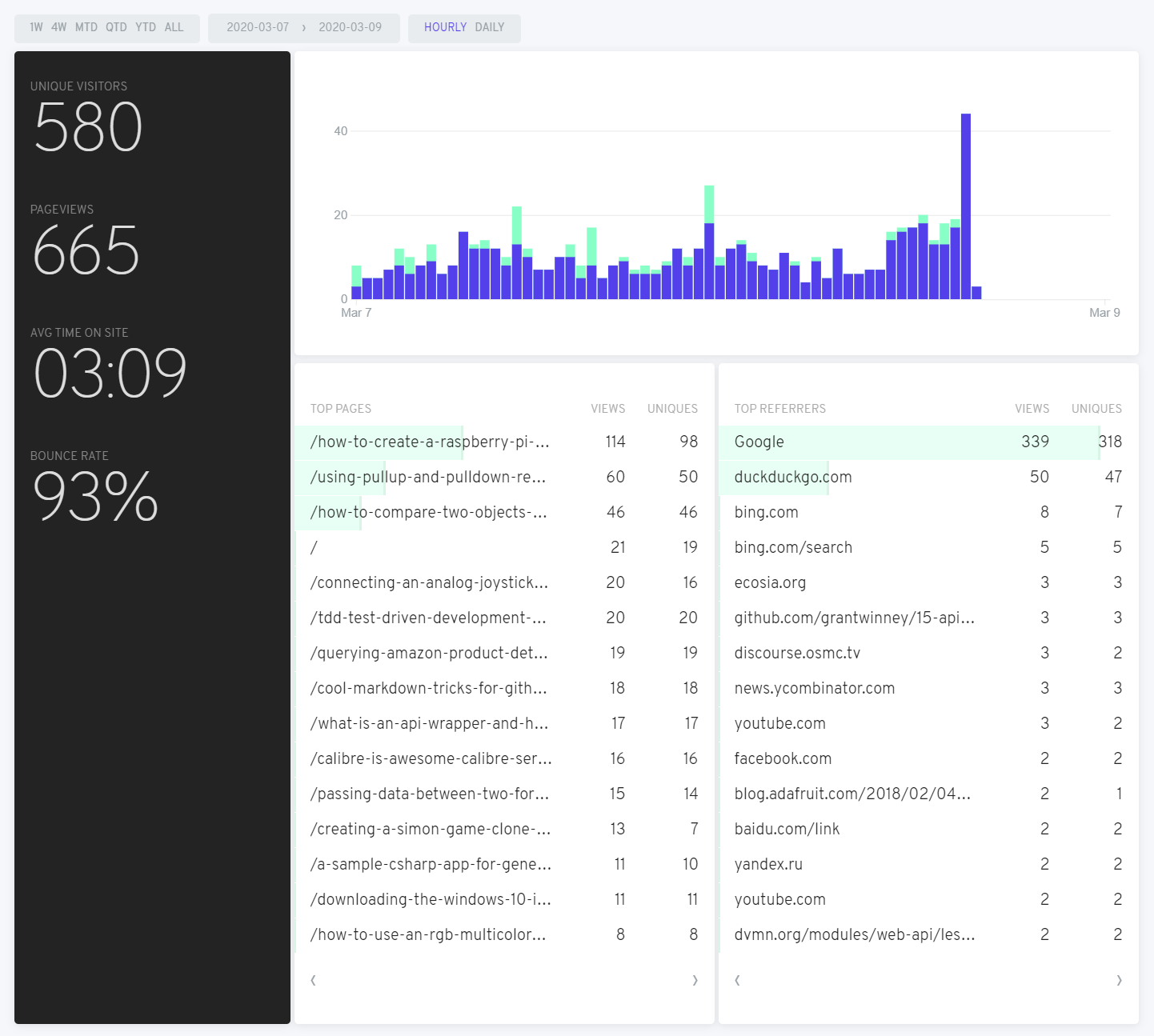
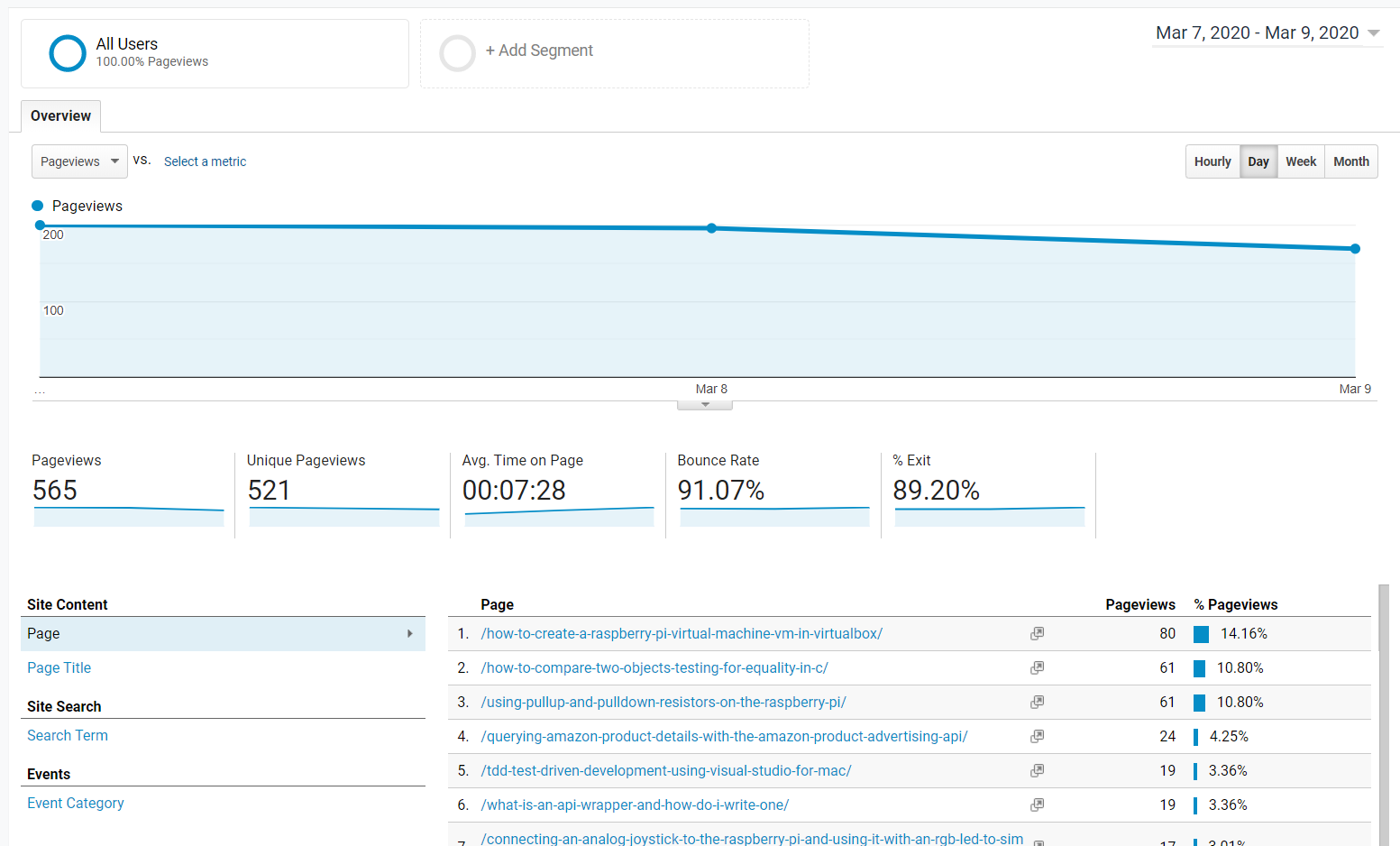
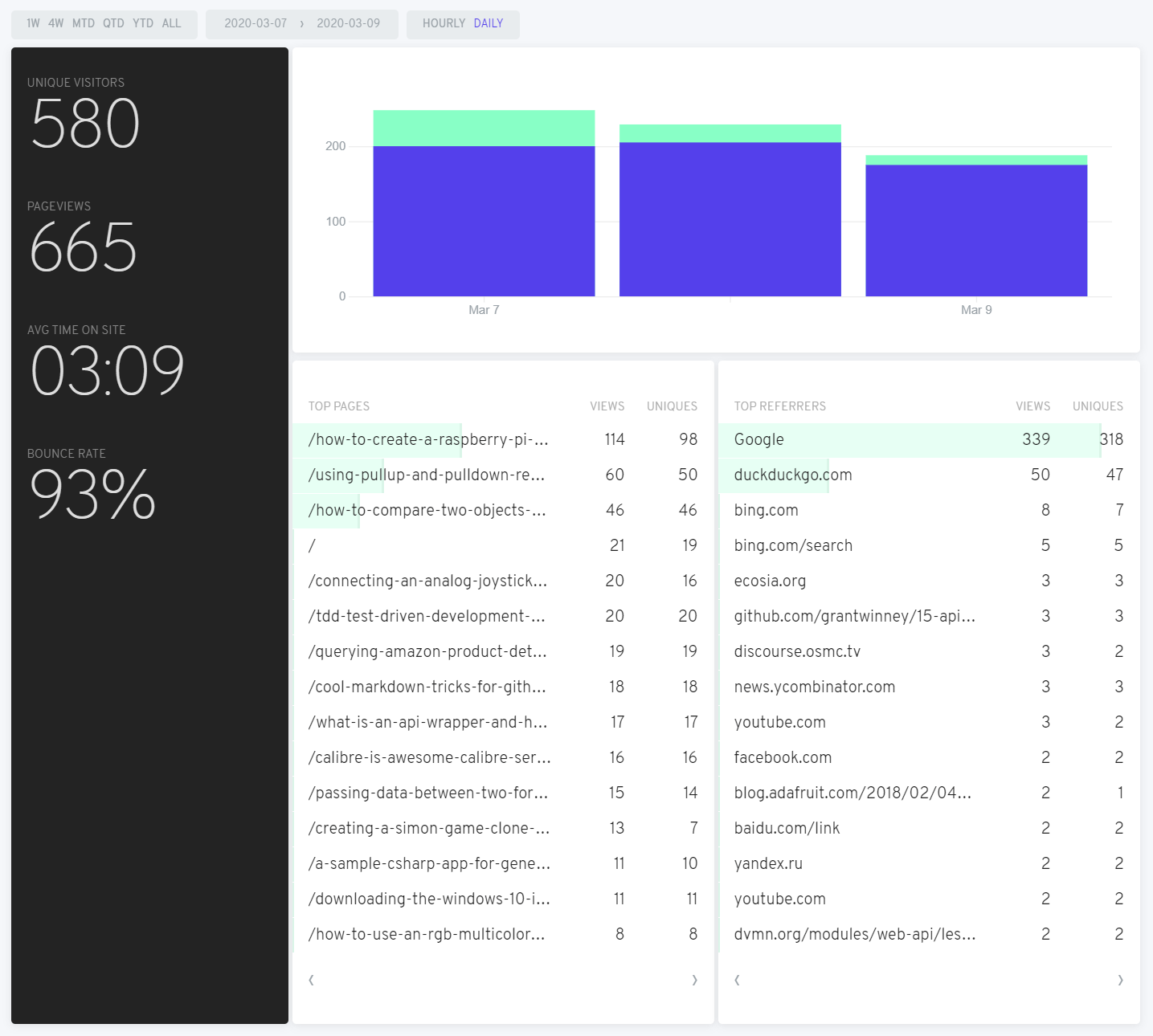
And here's 10,000 words.. er, 10 images comparing the results of Google to Fathom. In general, the numbers are similar though definitely not identical. General trends and spikes throughout the day seem on par. Popular pages (and referrals, not shown in the Google captures) are similar enough too, as is bounce rate (probably easy to calculate if the "referrer" is the same site).
The page views and numbers are fairly close, although they diverge when comparing several days. The numbers look a bit higher with Fathom, but that could be caused by adblockers (and possibly even some browsers) that block Google Analytics.
The average time per page seems to consistently be about half (or less) on Fathom than what Google reports. That's a metric I can't really wrap my head around though. It seems at best a guess, since there's an HTTP request when coming in to the site, but there's no indication of when a visitor leaves... or just closes the tab. Maybe if someone hits "back" to try the next hit on Google's search page, they can make a reasonable guess as to when a visitor left your page.
Anyway, I'm happy enough with the results to disable Google Analytics. Thanks Fathom! (disclaimer: IMO, YMMV, BOGO, YOLO, and any other acronyms you like...)
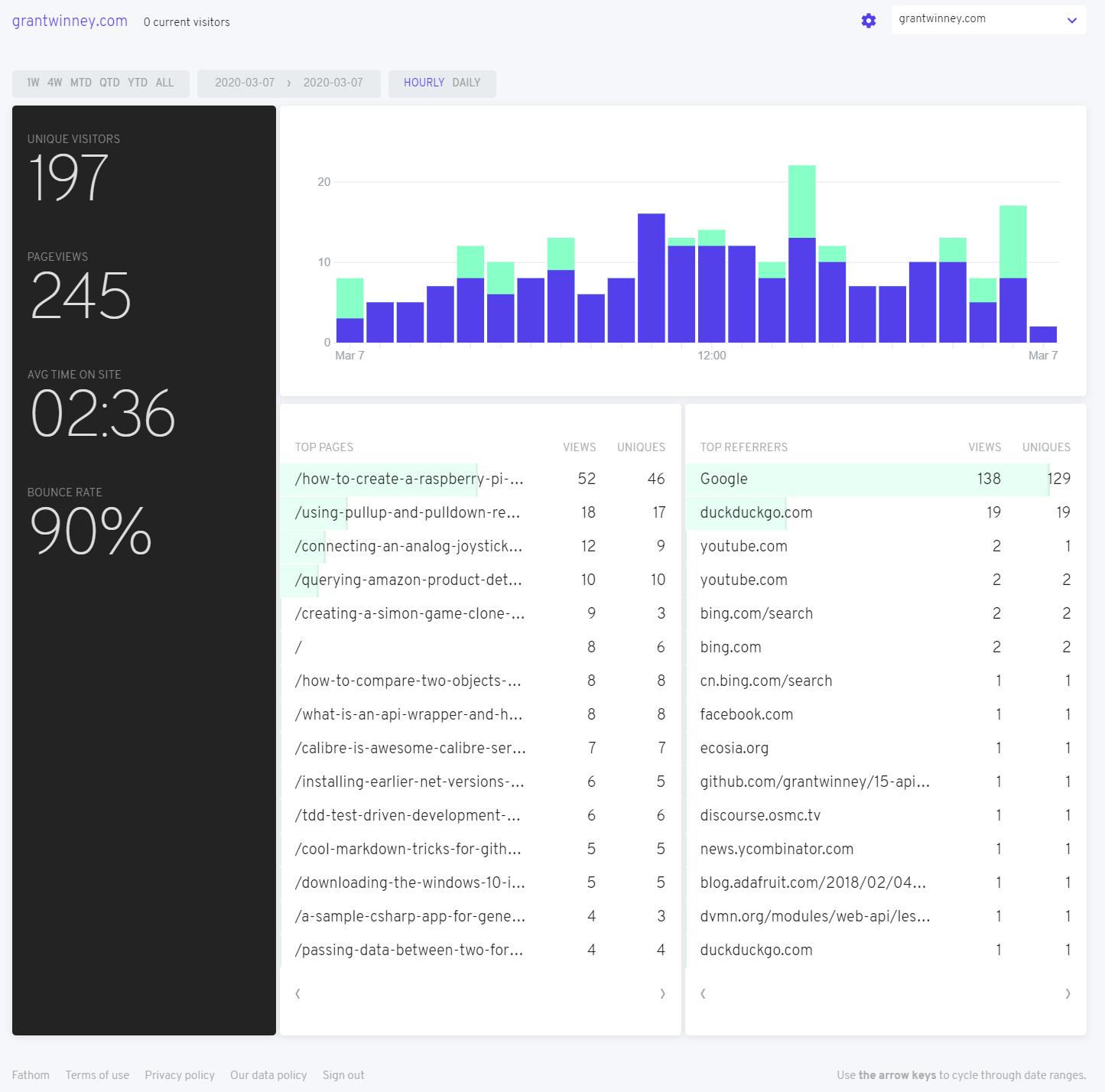
March 7 - First full day after installing
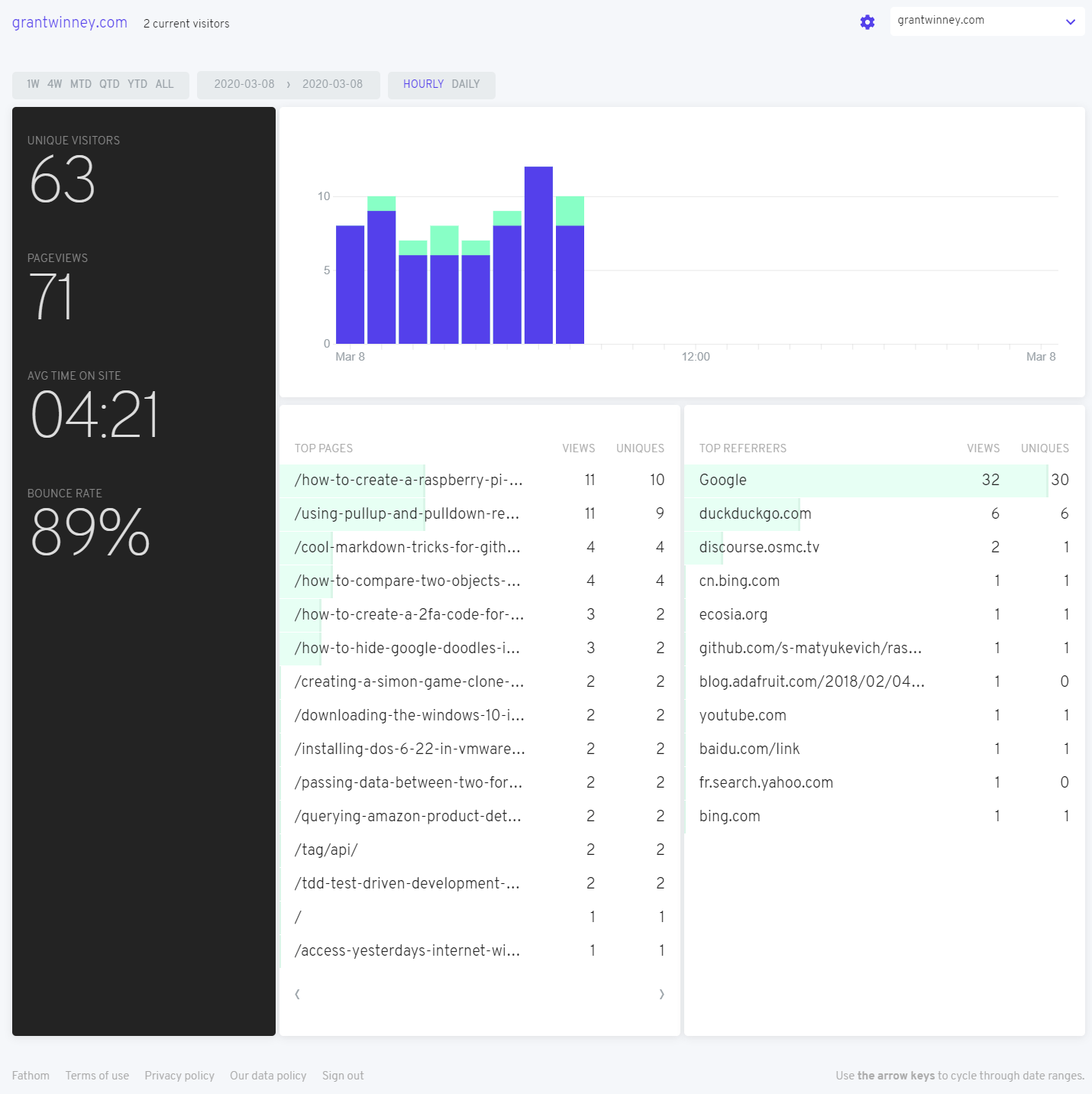
March 8 - Morning of the second day (the vertical line is the DST change)
If you find yourself in a position where you're supporting a WinForms application, you're likely to notice the tests... or lack thereof. Just because we may not have been so focused on automated tests and continuous integration when WinForms was younger, that doesn't mean we can't introduce them now. Better late than never!
Let's say you had an absurdly simple Form, like this one. It has 3 fields boxes to enter values (why? I dunno, it's pre-beta!), and an ADD button to, well you know, add them in the bottom box. The "Running Total" field never resets, but just keeps adding each total as long as the app is running.
Assume the above is implemented like this.. a relatively short bit of code. Too bad none of these methods can take advantage of automated testing. You'd need an instance of the Form itself, and every method is accessing or otherwise updating UI components. That won't do!
public partial class CalcForm : Form
{
public Form1()
{
InitializeComponent();
}
private void btnAdd_Click(object sender, EventArgs e)
{
decimal total = 0;
total += SafeGetNumber(txtNumber1);
total += SafeGetNumber(txtNumber2);
total += SafeGetNumber(txtNumber3);
txtTotal.Text = total.ToString();
txtRunningTotal.Text = SafeGetNumber(txtTotal) + total;
}
private void btnReset_Click(object sender, EventArgs e)
{
txtNumber1.Text = txtNumber2.Text = txtNumber3.Text = txtTotal.Text = "";
txtNumber1.Focus();
}
private decimal SafeGetNumber(TextBox tb)
{
return decimal.TryParse(tb.Text, out decimal res) ? res : 0;
}
}
What is MVP?
In a nutshell, it's one of many frameworks (MVP, MVC, MVVM, etc) that all try to do the same thing - separate the UI from the business logic. There are multiple reasons for this, but right now I'm focusing on the fact it makes it easier to test the business logic.
MVP achieves this in 3 parts - a View, a Presenter, and a Model... and some interfaces thrown in for good measure. A quick disclaimer first - no doubt there are more ways to implement MVP than what I'm about to present, but keep in mind the end goal. We want to separate the UI from most of the rest of the code.
The "View" represents the Form itself, and it includes an interface that represents everything you might need to get from (or set to) the Form, which is then used by the "Presenter" (more on that later) to tell it what to display next. Whereas before the View (your Form) had all the code neatly tucked away inside it, it's now very bare.
Here's how I converted the Form. Note that it's actually doing nothing intelligent now, other than wiring up all the UI components to various properties of the interface. Also note that I took the button click event handlers out of the designer file (where they automatically get created), and made those part of the interface as well. When a button's clicked, the Presenter will be know about it, and can act on it.
public interface ICalcView
{
event EventHandler Add;
event EventHandler Reset;
string Value1 { get; set; }
string Value2 { get; set; }
string Value3 { get; set; }
string Total { set; }
string RunningTotal { set; }
void Show();
}
public partial class CalcForm : Form, ICalcView
{
public event EventHandler Add;
public event EventHandler Reset;
public CalcForm()
{
InitializeComponent();
btnAdd.Click += delegate { Add?.Invoke(this, EventArgs.Empty); };
btnReset.Click += delegate
{
Reset?.Invoke(this, EventArgs.Empty);
txtNumber1.Focus();
};
}
string ICalcView.Value1
{
get => txtNumber1.Text;
set => txtNumber1.Text = value;
}
string ICalcView.Value2
{
get => txtNumber2.Text;
set => txtNumber2.Text = value;
}
string ICalcView.Value3
{
get => txtNumber3.Text;
set => txtNumber3.Text = value;
}
public string Total
{
set => txtTotal.Text = value;
}
public string RunningTotal
{
set => txtRunningTotal.Text = value;
}
}
The Model
The "Model" represents some object that you're operating on. In my case, I made the Model a sort of calculator object that stores the totals and does the actual summing up. What you put in here is a bit subjective, but just keep the end goal in mind.
public interface ICalcModel
{
decimal Total { get; }
decimal RunningTotal { get; }
void CalculateTotal(List<decimal> numbers);
}
public class CalcModel : ICalcModel
{
public decimal Total { get; private set; }
public decimal RunningTotal { get; private set; }
public void CalculateTotal(List<decimal> numbers)
{
Total = numbers.Sum();
RunningTotal += Total;
}
}
The Presenter
So far, we've got a View that displays nothing, and a Model that stores numbers but can't do much else. What's the glue that ties them together? I present.. the Presenter!
The Presenter doesn't have an interface, at least not the way I designed it. But it does accept the interfaces that the View and Model implement, and it operates on those. It orchestrates everything, subscribing to events in the View, getting data from the View, passing that data to the Model, and moving things back and forth as needed.
Note that it doesn't actually touch the UI though.. just passes things back to the View, which pops it into the UI where the user can see it.
public class CalcPresenter
{
readonly ICalcView view;
readonly ICalcModel model;
public CalcPresenter(ICalcView view = null, ICalcModel model = null)
{
this.view = view;
this.model = model;
this.view.Add += Add;
this.view.Reset += Reset;
this.view.Show();
}
public void Add(object sender, EventArgs e)
{
model.CalculateTotal(new List<string> { view.Value1, view.Value2, view.Value3 }.ConvertAll(TryGetNumber));
view.Total = Convert.ToString(model.Total);
view.RunningTotal = Convert.ToString(model.RunningTotal);
}
public void Reset(object sender, EventArgs e)
{
view.Value1 = view.Value2 = view.Value3 = view.Total = "";
}
public decimal TryGetNumber(string input)
{
return decimal.TryParse(input, out decimal res) ? res : 0;
}
}
Why should I care?
"Ugh", you might be thinking. "This is sooOOooOOooOo much longer than before", you might be thinking. You're right, it is. But it's also a lot more intentional, and a lot more separated out. And it allows us to mock the interfaces and thoroughly test the logic in the Presenter and Model, like this.
The end result? The beginnings of an automated test suite! You can plug this into TeamCity, Jenkins, or another CI tool and begin to get automated test runs. Yes, this is a lot more difficult in a large app that's been around for years, but with effort it's absolutely doable, one step at a time.
GitHub, in turn, is the defacto Git platform, tacking on a bunch of fancy tooling around Git. So your issues and PR's are right there, you get a wiki for documentation, a "project" board, a UI that lets people manage their repos without resorting to the command line, etc, etc.
The experience isn't always the best it could be, though. The UI tends to make poor use of available screen real estate, the wiki experience is subpar, and the project area is (afaik) tied to a single repo which is pretty unrealistic in an enterprise setting.
Where GitHub fails to impress, browser addons (and the services they tie into) can pick up the slack, so here's 13 addons (plus a few honorable mentions) that will take your GitHub experience to the next level!
If an addon hasn't been touched in years and doesn't seem to be actively maintained, I might exclude it.
I only included addons that solve one (or a few) problems, not general addons that address every issue under the sun.
These are listed in the Chrome store, but easily work for Brave and Operatoo. If there's a Firefox version too, I listed it.
One more thing.. shockingly, after installing all of these addons to test them out, none of them seemed to get in each others way. Let's just take a moment to appreciate that fact, shall we? 😮
What is an Access Token? (READ FIRST)
Most of these addons use the GitHub API, so what you experience when using them (and what you read in their docs) starts to look pretty similar. GitHub allows you to use their API without telling them who you are, but at a severely limited rate and only for public resources. Like, on the order of 60 requests/hour vs 5000 requests/hour for authenticated requests!
Needless to say, unauthenticated requests can run out pretty quickly if you're using GitHub a lot, and most of us are, so you want to create access tokens when possible. You could create a single access token with every permission possible, and plug it into each of the following addons when they ask for it, but then you may as well just give each of the addons your username and password. 🙄
What I'd highly suggest is to create a new, separate token for each addon,with a note that indicates which addon it's for, and give it only the permissions the addon needs. Most of the addons include a link in their respective Options pages that includes just the permissions it needs. If you decide to remove an addon, delete the access token associated with it too!
Alright, enough of that! On to the main attraction...
If you need to do a little debugging on a repo, you have to clone it locally and open it in your favorite IDE or code editor, something that can be expensive (time-wise) if you just need to take a quick peek. Well you had to clone it, anyway.
Sourcegraph is an IDE for the browser that works with multiple languages. Just hover over a keyword or identifier in your codebase, and the addon pops up a link that takes you to sourcegraph's site, which in turn provides syntax highlighting and click-through navigation for your application. I tried it with a C# application I wrote for a recent post on MVP, and it had no problem navigating around.
Sourcegraph brings the IDE experience to your browser
It's free to use for small teams, and you can install it on premise for free too. Their future goals are lofty, to say the least. It seems they'd like to replace the need for separate, local IDEs using a protocol called LSP, and to eventually have a global graph of all OSS to make it easier to find and share code. 🤯
Alternative: Octohint(source code) appears to do something similar, although I didn't try it out and I have no idea how it's implemented.
Once you've installed sourcegraph, you can navigate your codebase from your browser like a pro, but what about when you need to find a certain file in the first place? You have to either click through multiple levels of directories, or use GitHub's built-in file search function, which is powerful but a little cumbersome.
Octotree produces a file explorer style "directory structure" view of your entire repo. Just expand to the file you need, and click the name to go to that file or click the arrow to the left of it to see the "raw" version of the file. I think this complements sourcegraph really well, and makes the IDE experience in the browser that much more awesome.
Octotree gives you a file explorer style view of your repo
Bonus: The pro version of Octotree includes a host of extra features, but if the only one you're interested in is a dark mode, the GitHub Dark Theme addon does a nice job. Hmm, I think the darker styles make file icons and other highlighting colors really pop out... what do you think?
One of the toughest things to grok when you join a new team, is to figure out where everything is. Where the source code is, where the issues and PR's related to that source code are, where the project management that organizes and prioritizes the stories related to those issues and PR's are... where the internal documentation lives, where the external documentation lives, and on and on and on...
If you can keep your tools in a single area, it makes life that much easier. I haven't played with GitHub's projects much, but they seem tied to a single repo. In my experience, a single team working on a single project might actually be committing changes to several (or dozens) of related repos.
ZenHub lets you group a bunch of projects into a single "workspace", and then integrates itself smoothly into the GitHub UI, so you can manage the workspace from any repo. I was able to easily group two related repos, pull in their issues, move the cards around, and even mark an issue in one repo as "blocked" by an issue in the other repo.
ZenHub tracks progress across multiple repos, right from the GitHub UI
The ZenHub board is a kanban style, where you can easily drag issues (and PR's, etc) around the board to indicate what their current status is. It's free for personal, public repos too, so check it out.
GitHub shows a generic text file icon for every file, regardless of its type. Considering colors and shapes were the first things most of us learned, I think GitHub could do a little better. GitHub File Icons brings the same as Octotree (which come from the Atom editor) into the main GitHub UI. So if you use Octotree, this fits in really nicely.
GitHub File Icons add file type specific icons (optionally with color)
Alternative: The github-vscode-icons addon (source code) uses icons from VS Code, which IMO stand out much better. I find the other icon colors a bit washed out. Presently though, this addon seems to have an issue checking for updated icons.. they appear for a moment, then all change to a small "loading" icon until you refresh the page. So ... kinda broken unfortunately. :(
Vanilla GitHub vs GitHub File Icons vs github-vscode-icons
Did you know you can store any type of file on GitHub, with files up to 100 MB and repos up to 100 GB (although they recommend 50 MB and 1 GB, respectively, for top performance)? That being said, you need to have a legitimate reason for files and repos that large, but assuming there is one, wouldn't you like to know it before cloning some 5 GB repo to your local disk?!
Enhanced GitHub displays the size of the repo right above the"Clone" button. It also displays sizes of individual files, which is cool although I don't find that as useful. Another feature that I do like though is "Copy File", which.. um... copies the current file to your clipboard. Kinda self-explanatory, now that I think about it.
View a repository's size before deciding to clone
Regarding privacy, similar to the other addons, it can't access private repos unless you create an access token, but again you might as well so you don't hit the unauthenticated API rate limit.
One of the ways I use GitHub is to upload code samples from various posts I've written, going back several years. I create a new directory for the blog post in that repo, then upload the code to that directory, and link to it from the post. It's sorta like Finder or Windows Explorer, except you can't download just the directory.. you have to clone the entire repo and dig around in it! Until now...
GitZip lets you click on one or more files or directories (actually, you have to click the white space next to the name), and then you get a handy "download" button for your selection, which gets (gits?) you a zip file. Who says naming things is hard?
This complements the Enhanced GitHub addon pretty well - if you find out a repo is too large and you don't want to bother cloning it, use GitZip to download just the parts you are interested in! I can imagine other sites where this would be useful, like programming books that upload the related code to a repo, one lesson or exercise per directory.
After a couple tries, I hit my unauthenticated limits. Just click the GitZip icon to create an access token, and you'll be back in business.
There are times when you fully expect an app won't use all your screen real estate.. playing a retro PC game, or installing Windows 3.1 for example. But in a modern web app, there's no reason not to take advantage of a wider screen. For some reason though, GitHub doesn't and (AFAIK) never has.
Wide GitHub applies some CSS that takes full advantage of your 32:9 super-duper ultra-mega-wide curvy monitor. Now your GitHub code can wrap all around you, like a giant omnimax theater.. for code. But if you hit a page that seems less readable in wide format, just click the icon to disable it.
If you already use Stylus (or Tampermonkey, etc), there are instructions on how to use them instead. But the addon is easier and you'll get automatic updates, so there's that... decisions, decisions.
When you come across a broken GitHub link, you get a 404 - no surprises there. The problem is, the 404 page doesn't tell you if the entire repo is gone, or the branch that was linked was merged back to master, or just the linked file was deleted. Your forced to do some digging to figure out which might be true.
If everything goes well and you never come across a broken link, then you'll never even notice GitHub 404 Breakdown. But when you inevitably do hit a broken link, then this nice little addon tests every portion of the URL and lets you know exactly where things broke down.
GitHub Issue Link Status (inline issue and PR statuses)
It's amazing how something as straight-forward as adding a little color can instantly tell you something important, eliminating the need to have to spend a couple extra brain cycles thinking about it.
GitHub Issue Link Status does just that, adding different colors and icons to issues and PRs, dependent on whether they're open, closed, or merged. And it seems to work all over the GitHub interface, not just the issue or PR screens.
Commit a file with tabs in it, and then open it on GitHub. Oddly, if you edit the file right on GitHub, you can choose between a few sizes for tabs. But if you just want to view the file (far more likely), you get 8 spaces per tab. Maybe it's GitHub's way of showing you the truth... spaces are better! *ducks*
When editing a file, you can choose 2, 4, or 8 spaces for tabs... but not when viewing!s
The GitHub Custom Tab Size addon gives you an easy way to change that, especially helpful if you're working in a codebase with deeply nested code. Yeah yeah, this can be a sign of a code smell.. but until you manage to refactor that old codebase that's 20 levels deep, this addon might help preserve your sanity.
Better Pull Request for GitHub (navigation for large PRs)
If you've been doing PRs as a team for any length of time, sooner or later you'll come across a simply massive PR. It might be 2 lines changed in each of 100 files, or a project that kept increasing in scope across too many sprints. Whatever happened, it'll be daunting to scroll through, in part due to the fact that GitHub just lays out all the file changes without any sort of navigation or table of contents.
Better Pull Request for GitHub generates a table of contents (only when you're viewing a PR) that looks very similar to the navigational explorer window you'd find in nearly any IDE. Clicking a link takes you right to the file in question, and as you scroll the looooong PR, the selected file actually changes depending on where you are on screen.
Although Octotree is collapsed here, it plays nicely with the navigational tree that Octotree creates too. Better Pull Request inserts its panel into the PR page smoothly, making it appear like it's just another part of the UI.
OctoLinker (links libraries to their official docs)
This one definitely follows in the suit of other addons that enhance GitHub to make it more of an IDE experience right in your browser. Every application you write, regardless of the language, will depend on other libraries. If you see a reference to a library, you have to manually look it up.
OctoLinker looks at the file type, and if it's a supported language (like Python, Ruby, JavaScript, etc), it inserts links for any libraries it finds to their respective docs.
It's supposed to work for relative file references between your files too, but the only thing I had to try it on were some Python scripts, and it didn't work with those.
GitHub has a spiffy Notifications area that alerts you to all kinds of things like assigned issues and PR's, threads you commented on, other people @mentioning you, etc. I'd suggest going into your notification settings and deciding what exactly you even want to be notified on. You'll notice they come in 2 flavors - via the UI if you have GitHub open onscreen, and via email.
If you want to know about new notifications, but you neither need more emails nor leave GitHub visible all day, then checkout Notifier for GitHub. It's so simple there's nothing really to show.. it displays an icon in your toolbar with a notification count, and clicking on it opens the GitHub notifications page.
Oh look, I found something to show anyway. 1 unread item is offscreen.
It's just making a call to the Notifications API, which returns a JSON block with detailed info about your notifications, and then it counts the number of returned items. Actually, since the author has access to all that data, I wish there was an option to hover over the toolbar icon and see a brief summary of the newest notifications, but oh well. It's nice anyway, if you're trying to stay on top of alerts.
Sounds like an opportunity for the author to rework the addon...
Honorable Mentions
Some addons look promising, but aren't quite ready for prime-time yet. Others are popular, but try to fix everything instead of focusing on one thing. Here are some addons I came across that are worth a look, but I
Paint GitHub (a picture is worth a thousand words)
A picture is worth a thousand words, especially when you're trying to describe a problem you're having. Paint GitHub adds a new tab with a canvas to the "New Issue" screen, allowing you to create a freehand drawing and then "upload" it to GitHub for attachment. If you want to draw over an existing image, like maybe a screen capture of the problem you're having, you can insert it with "Insert image".
It appears to be in the early stages of development, but I hope the author continues with it. You can draw free-hand but not much else - it'd be great to have all the basic functions of a "paint" style app like adding text and geometric shapes, etc. But... it works as-is and (for some cases) eliminates the need to edit an image in a separate paint app and then drag it over to the "New Issue" panel.
It's pretty self-explanatory, allowing you to quickly add issues to a repo. Unfortunately, it only works for a single user or organization, not across all the organizations a person might belong too. Hope the author makes a few changes to it.
I didn't try Refined GitHub, but the author (who also wrote Notifier for GitHub, above) is prolific on GitHub for his OSS, and the addon is very highly rated. It's definitely worth checking out, but I'm personally not interested in an addon that fixes all the things for all the people.
Did you know it's completely within your grasp to change the look and feel of every website you visit? That's right... you can change colors, move things around, and completely hide anything that gets in your way! 💪 Let's learn how...
No matter how many people took part in designing a single webpage, how complex the process is to generate it before sending it to you, how fantastically awesome it appears when it finally renders in your browser, every webpage boils down to a few predictable pieces. It has to, so that any browser on any device can display it correctly and reliably.
There's the HTML markup that defines which elements you see (tables and labels and headers, oh my), JavaScript code that defines what happens when you press a button or enter an invalid email address, and CSS styles that define how the tables look and where the labels should be displayed. They're all applied/running/whatever locally in your browser, on your device, and you have the power to change them or even stop them from running.
There's another browser addon, called Stylus, that lets you write your own CSS styles to hide or otherwise manipulate web pages to your liking. You can keep them to yourself or share them with others. Before we get there though, here's a brief CSS primer. Feel free to skip if you already know CSS.
When you reference an HTML element on a page to change how it looks, you use something called a "selector"... just a fancy term for selecting an element by its type, ID, or class name. If you want to read all about selectors (or anything else web-related), check out MDN's excellent documentation, such as this one:
Until you read all that, here's a short example to make a few points. It applies a few styles based on type, ID, and class name, although you can get a lot more complicated when defining selectors to apply styles to an element.
When you're selecting elements on the page (aka DOM):
Select types by using the name of the element type. (i.e. div { ... })
Select classes by prepending a period. (i.e. .important { ... })
Select IDs by prepending a hash. (i.e. #notice { ... })
In the above markup, notice that:
All <div> elements are bolded and colored blue.
The elements with the "important" class on them are colored red.
The element with the ID of "notice" has a blue border around it.
The really important message is in a <div> block and has a class name of "important". So first, it's bolded and colored blue, but then the "important" class overwrites it and colors it red. That's the cascading part of CSS at play, where you can "layer" styles over one another.
Hiding elements - out of sight, out of mind
You can use selectors on your own, for example to create "dark mode" versions of sites that are too bright for your liking. Another popular use, which I alluded to before, is to completely hide elements you don't want to see, like sidebars with ads or recommended videos that pull you further down the rabbit hole. 🐇 🕳
It's fortunate that most sites create sensible class names and IDs for sections of their websites that you might want to hide, like <div id="ads"> or <div class="comments">. You can easily attach styles to those elements, like in the following snippet where I easily (one line!) hide an annoying sidebar full of distracting (and entirely realistic) advertisements.
Simplifying life with Stylus
I mentioned the Stylus addon earlier, and how it makes it easy to apply your own styles, share styles with others, and import styles from others. It's available for Chrome, Firefox and Opera.
There's more info in their wiki, but briefly... after you install it:
Open the site you want to make changes to.
Click the "Stylus" icon and select the URL of the site under "write style for".
Right-click the website and select "Inspect" to start looking for IDs and classes you can make changes to, then paste those into the Stylus panel that opens.
Finding the elements you want to modify
I'm not sure about Firefox, but Chromium-based browsers like Chrome, Opera, and Brave will highlight elements as you "inspect" the page, so you can clearly see which element is being referred to in the code. 👍
Some websites are really dynamic. In my experience, Facebook is the worst, with no IDs and class names that seem to be generated dynamically. It makes it really hard to find something reliable to reference.
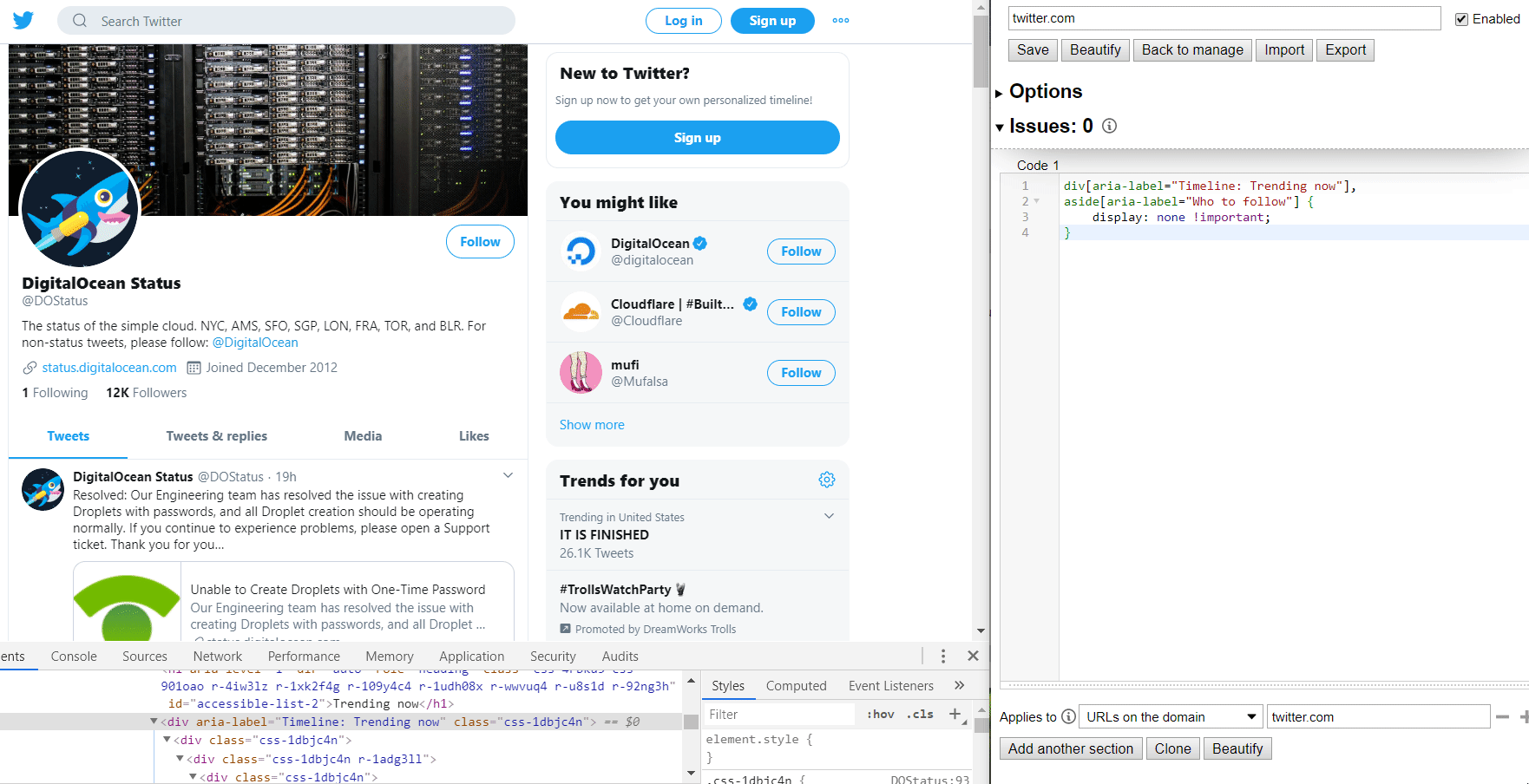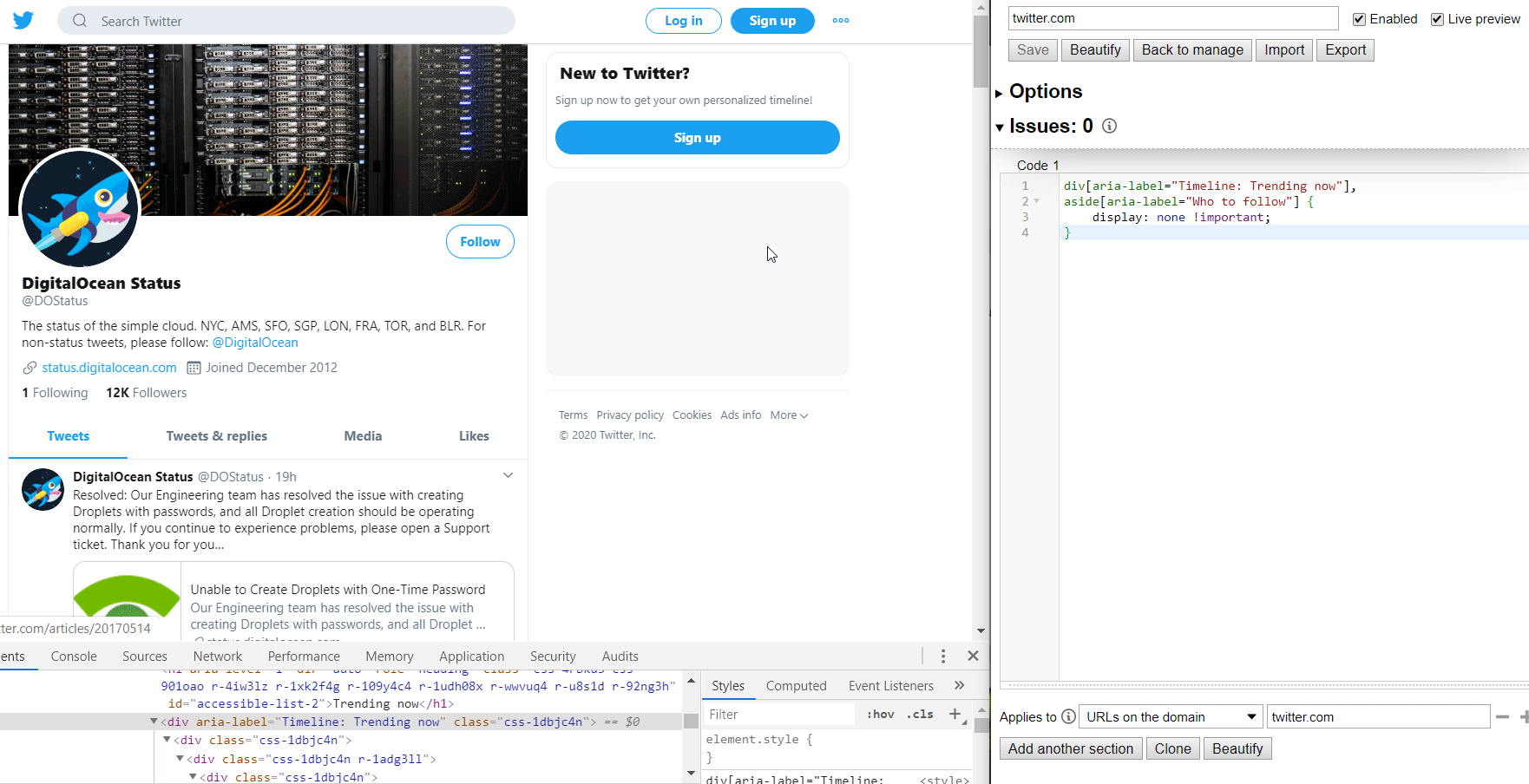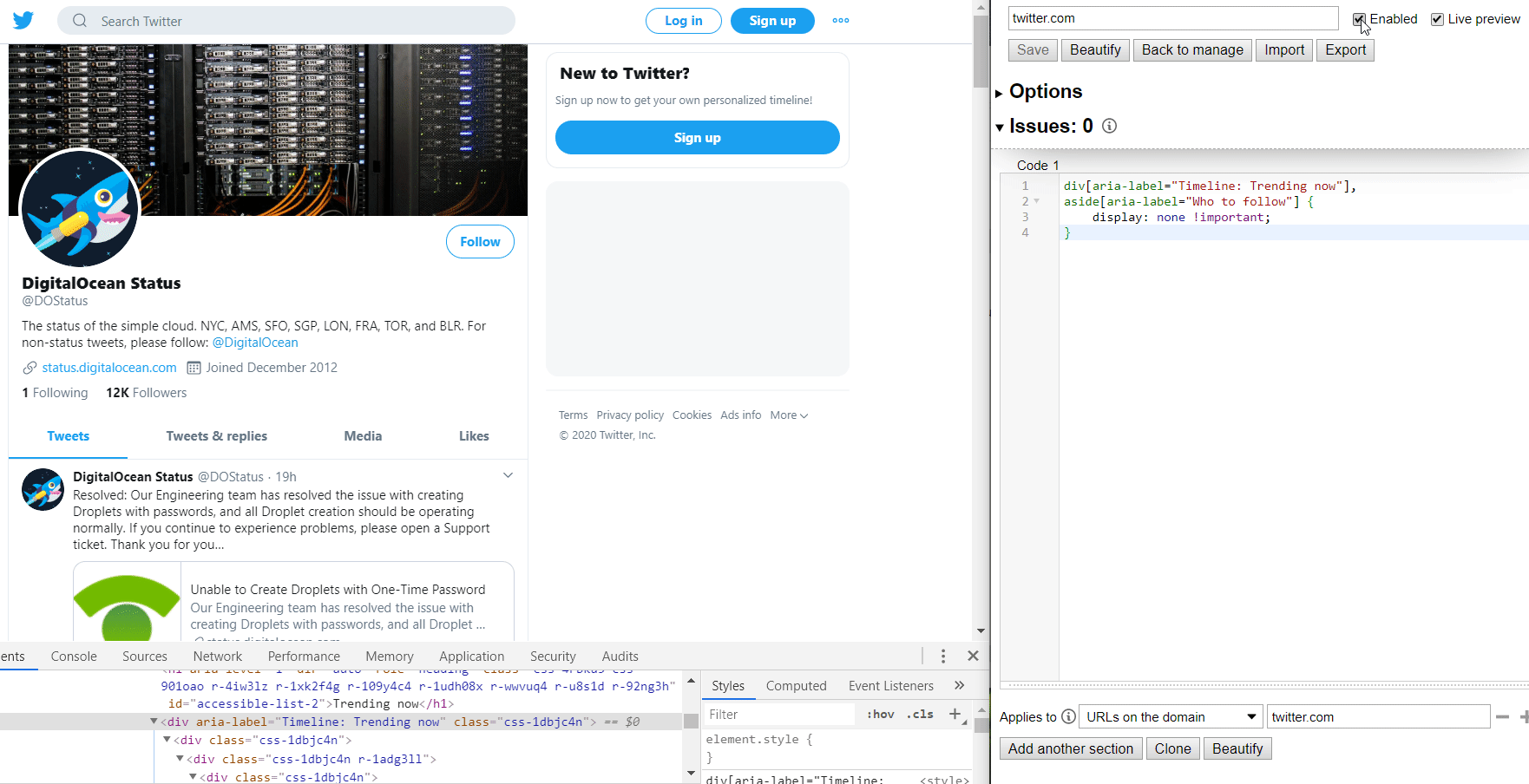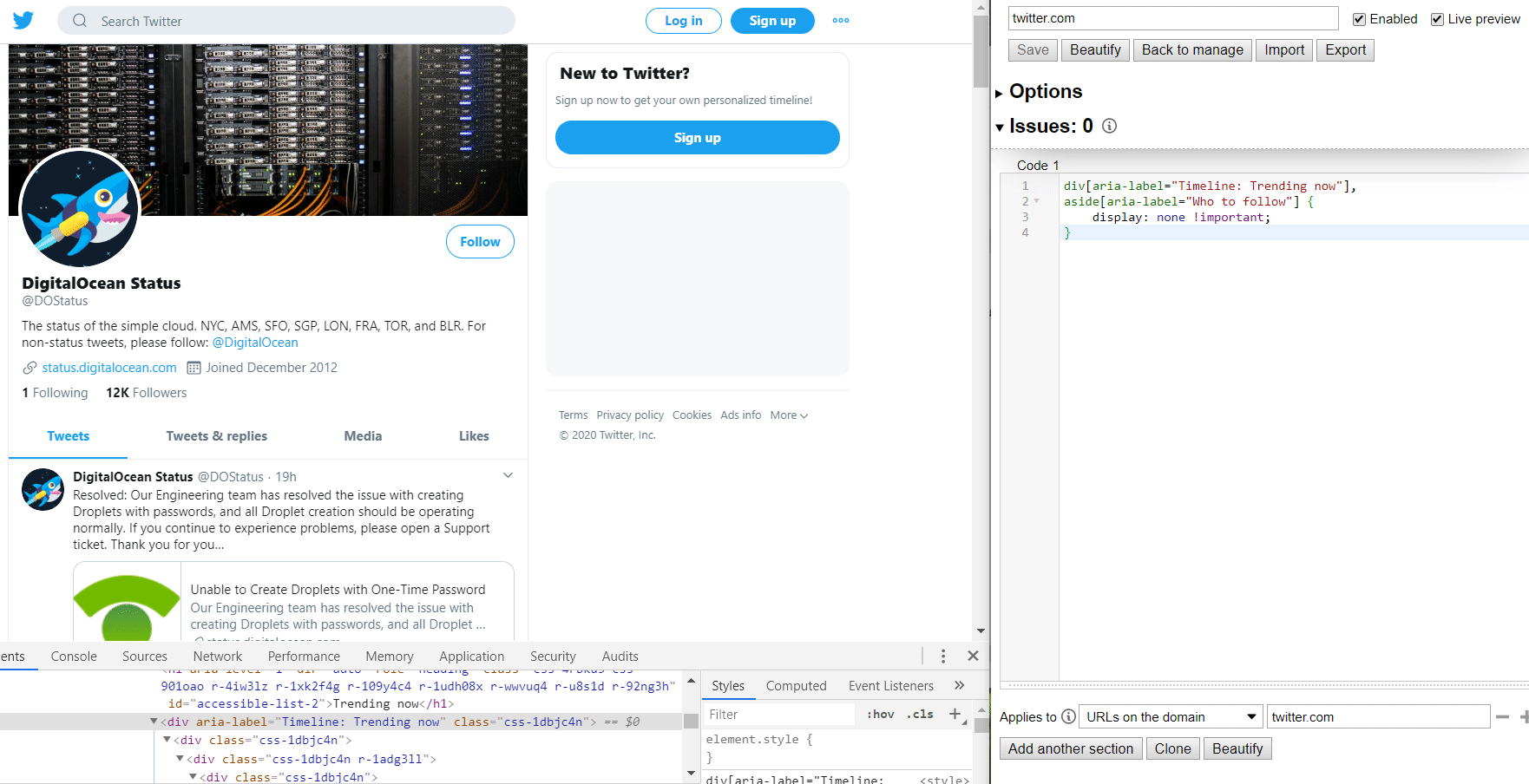
Twitter is slightly better, with fairly consistent "aria-label" attributes you can grab hold of. When I showed you the basic selectors above, I didn't show you how to use attributes, but they're easy too. We'll take a look at them next.
Now modify them!
Once you know which elements you want to modify, there's nothing left but to do it!
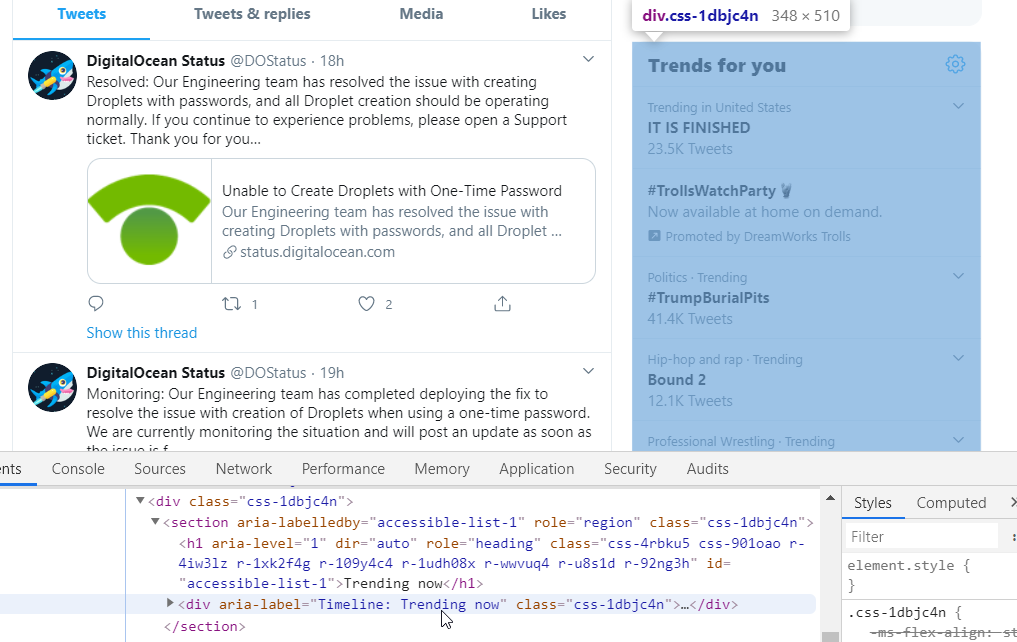
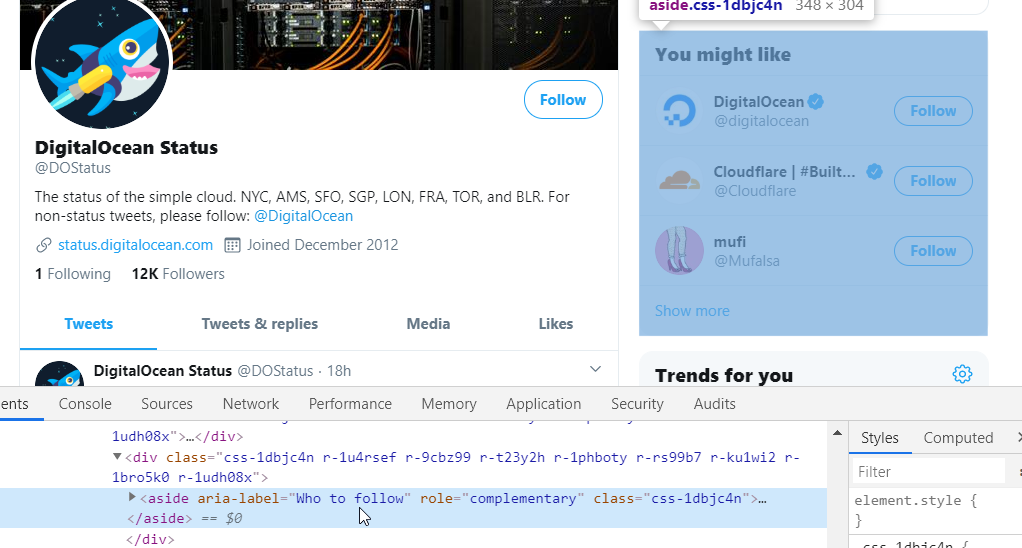
I mentioned Twitter so we'll use them.. they're great at finding ways to keep you on the site, which makes them a great candidate for modifications. I don't have an account, but quite a few businesses like to post system status updates there, so it's useful sometimes. The Trends section, and most everything else in the sidebar, is just a time-suck, so they can go.
Notice how attributes are referenced by enclosing them in square brackets. That's it! I included the element type (div, aside, whatever) to make it a bit more specific, but I could've just as easily left them out. Oh, and the !important flag isn't strictly needed either, but it ensures that your preferences override anything else on the page.
Don't reinvent the wheel!
If you put a lot of work into a style, you can share it anywhere you like. Just click the "Export" button and share the contents, which in my case look like this:
There are sites like UserStyles too, that allow you to upload and download all kinds of styles, which can then be imported into your local Stylus. Note that that particular site is associated with another extension called Stylish, which Stylus is based off of.. use Stylus.
I was doing some React training early this week, following the author's lead and writing a tiny app to load GitHub users' profiles. Truly awesome shtuff. I tested it out with a few real names, a random key mashing, and finally a single hyphen. I don't know why, it's unlikely to be a username. Or is it? dun dun DUNNN
A single hyphen for a username? 🤔
Well, for someone stuck inside with nowhere to go, that just begs to be looked into further. Is this an early user? A hidden test account of some sort? I immediately went to view their profile, but.. um... it can't be found. Oddness.
Yet I could find other people who had followed this slickest of peppers, and I was able to follow it too. But hovering over the profile name shows nothing, and in fact throws a 404 error in the console. More oddness.
At this point, I decided to leave the finicky front-end to its own devices, and see what I could see with the GitHub API. First stop, a simple request to grab user info. There's quite a few other endpoints in the response that may shed more light on just who this mystery pepper is.
It might be interesting to see who the account was following (pinch o salt? side o garnish?), but unfortunately a call to the /following endpoint returns an empty result set. Likewise, there are no gists or starred repos, organizations or events.
Ah. Could Mr Samour be the infamous Dash O Pepper? His account existed a year before it, so it was probably just a test account he made. But I take pride in my investigative work, so let's confirm it. You know, without actually just reaching out and asking him. That'd be too easy.
Dash O Pepper didn't have much, but it was watching some repos (aka subscriptions), 5 of which belonged to Acumen Brands Inc, WHICH! just happens to be... um, well.. a place Rogelio Samour worked aaand that's enough yikes I'm stopping right now before I creep myself out anymore. Suffice to say, I feel confident that it was him. Is him. Whatever.
What a roller coaster of emotions, huh? No? Anyway, I mirrored the repo, with its one file and one commit, and I'll try not to convey any disappointment that it held no answers to the mysteries of our universe. Here it is. 🥱
There is one thing I was left wondering though. How was a username like this possible in the first place? And if it was before, why not now? Why is GitHub's front-end sploding every which way when trying to access it?
After a little google-fu I found a high-security bug, found by employees of GitLab and GitHub, and patched a few years back (details here and here). Seems there were really bad potential side effects for host names starting with a hyphen. To play it safe, they disabled using a hyphen elsewhere too.
A malicious third-party can give a crafted "ssh://..." URL to an
unsuspecting victim, and an attempt to visit the URL can result in
any program that exists on the victim's machine being executed.
Such a URL could be placed in the .gitmodules file of a malicious
project, and an unsuspecting victim could be tricked into running
"git clone --recurse-submodules" to trigger the vulnerability.
Credits to find and fix the issue go to Brian Neel at GitLab, Joern
Schneeweisz of Recurity Labs and Jeff King at GitHub.
* A "ssh://..." URL can result in a "ssh" command line with a
hostname that begins with a dash "-", which would cause the "ssh"
command to instead (mis)treat it as an option. This is now
prevented by forbidding such a hostname (which should not impact
any real-world usage).
* Similarly, when GIT_PROXY_COMMAND is configured, the command is
run with host and port that are parsed out from "ssh://..." URL;
a poorly written GIT_PROXY_COMMAND could be tricked into treating
a string that begins with a dash "-" as an option. This is now
prevented by forbidding such a hostname and port number (again,
which should not impact any real-world usage).
* In the same spirit, a repository name that begins with a dash "-"
is also forbidden now.
Not in the naming of a repo apparently, unless internally a repo includes your username. And if you take another look at what the API returns, the "full_name" of a repo does include your username, which they no longer allow to begin with a hyphen. So... there you have it, another mystery solved. You're welcome. 🙄
As for the whole weird system behavior, it's probably just the code running into various checks and balances and whatever else, when what should've happened was that user was renamed to something that's considered valid in the system.
Wonder what other user names starting with a hyphen are still hanging out there?
The difference between a family shop and a mega-chain is passion, expertise, and personal touch vs larger selection, cheaper prices, and more generous warranties and return policies. If I need expert advice for a new project, I prefer a smaller shop with a personal touch. If I need several tons of gravel or contractor levels of mulch, I hit up Lowe's - I don't want advice, just a lower price tag.
Taken to an extreme, let's imagine a store where the selection is nearly limitless, the cost is free (as in money), but the personal touch is non-existent. The only way a place like that would survive is if they found out some other way to make money (say, selling information about you), and convincing the world that what they offer is so valuable people will never leave despite their abysmal customer service.
A few months ago, I pushed a minor update to an extension that's lived happily in the Chrome web store for years without a problem, but I won the sucky lottery. What follows is a series of emails trying to figure out what I could do to fix the problem. What a waste of time. 🙄
Google (let's play a guessing game)
tl;dr: Let's play a guessing game! We'll flag your code for permissions, and you guess which one! What? We specialize in machine learning, not people learning...
Your Google Chrome item "Twitter Tamer" with ID: aflapchiclhldkgbbahbdionenmhkoed did not comply with our policies and was removed from the Chrome Web Store.
Your item did not comply with the following section of our Program Policies:
"User Data Privacy"
Your product violates the "Use of Permissions" section of the policy, which requires that you:
Request access to the narrowest permissions necessary to implement your product’s features or services.
If more than one permission could be used to implement a feature, you must request those with the least access to data or functionality.
Don't attempt to "future proof" your product by requesting a permission that might benefit services or features that have not yet been implemented.
Once your item complies with Chrome Web Store policies, you may request re-publication in the Chrome Web Store Developer Dashboard. Your item will be reviewed for policy compliance prior to re-publication.
If you have any questions about this email, please respond and the Chrome Web Store Developer Support team will follow up with you.
Important Note:
Repeated or egregious policy violations in the Chrome Web Store may result in your developer account being suspended or could lead to a ban from using the Chrome Web Store platform.
This may also result in the suspension of related Google services associated with your Google account.
Sincerely,
Chrome Web Store Developer Support
I checked online to verify, and sure enough:
Me
tl;dr: Which permissions?
2/6/2020 1:14 PM
What?? I request access to "activeTab" and "storage" (for saving settings), and the "matches" section is only for Twitter's domain. If you see a way to limit that more and have the extension still function, by all means please share.
Google
tl;dr: Déjà vu
2/9/2020 6:34 AM
Dear Developer,
Upon review of your Product, [Twitter Tamer ], with ID: [aflapchiclhldkgbbahbdionenmhkoed], we find that it does not comply with the Chrome Web Store’s User Data Policy, and it has been removed from the store.
Your Product violates the “Use of Permissions” section of the policy, which requires that you:
Request access to the narrowest permissions necessary to implement your Product’s features or services. If more than one permission could be used to implement a feature, you must request those with the least access to data or functionality.
Don't attempt to "future proof" your Product by requesting a permission that might benefit services or features that have not yet been implemented.
To reinstate your Product, please ensure that your Product requests and uses only those permissions that are necessary to deliver the currently stated product’s features.
If you’d like to re-submit your Product, please modify your Product so that it complies with the Chrome Web Store’s Developer Program Policies, then re-publish it in your Developer Dashboard.
Please reply to this email for questions / clarifications regarding this Product removal.
Thank you for your cooperation,
Google Chrome Web Store team
Me
tl;dr: @#&$!
2/9/2020 7:40 AM
It took 2 days for someone to send the same canned response?! Let's try again.
I request access to "activeTab" and "storage" (for saving settings), and the "matches" section is only for Twitter's domain. I need to know exactly what to change to be approved. What specific change do I need to make to the permissions?
Google
tl;dr: Okay yeah, the first one you mentioned. Remove that one.
2/10/2020 7:12 AM
Dear Developer,
Upon review of your Product, Twitter Tamer, with ID: aflapchiclhldkgbbahbdionenmhkoed, we find that it does not comply with the Chrome Web Store’s User Data Policy, and it has been removed from the store.
Your Product violates the “Use of Permissions” section of the policy, which requires that you:
Remove activeTabs permission.
Request access to the narrowest permissions necessary to implement your Product’s features or services. If more than one permission could be used to implement a feature, you must request those with the least access to data or functionality.
Don't attempt to "future proof" your Product by requesting a permission that might benefit services or features that have not yet been implemented.
To reinstate your Product, please ensure that your Product requests and uses only those permissions that are necessary to deliver the currently stated product’s features.
If you’d like to re-submit your Product, please modify your Product so that it complies with the Chrome Web Store’s Developer Program Policies, then re-publish it in your Developer Dashboard.
Please reply to this email for questions / clarifications regarding this Product removal.
Thank you for your cooperation,
Google Chrome Web Store team
Note that all "ActiveTab" pretty much does is give you access to the current page only when the user clicks your extension's icon in the toolbar. I used it to enable/disable the extension and offer to refresh the page for the user, only if they were actually on Twitter's site.
I made a grave mistake and tried to appease the system, removing the permission and completely harmless functionality. I uploaded it an went to be, confident that my effort would be worth it for a few hundred people at least. The next morning, I got another email, flagging the extension for a completely different reason.
Google (or maybe whack-a-mole)
tl;dr: Making you remove storage would be kinda odd. Okay you know what, your extension's fishy. Fix that please.
2/11/2020 5:09 AM
Dear Developer,
Your Google Chrome item "Twitter Tamer" with ID: aflapchiclhldkgbbahbdionenmhkoed did not comply with our policies and was removed from the Chrome Web Store.
Your item did not comply with the following section of our Program Policies:
"Spam and Placement in the Store"
Item has a blank description field, or missing icons or screenshots, and appears to be suspicious.
Once your item complies with Chrome Web Store policies, you may request re-publication in the Chrome Web Store Developer Dashboard. Your item will be reviewed for policy compliance prior to re-publication.
If you have any questions about this email, please respond and the Chrome Web Store Developer Support team will follow up with you.
Important Note:
Repeated or egregious policy violations in the Chrome Web Store may result in your developer account being suspended or could lead to a ban from using the Chrome Web Store platform.
This may also result in the suspension of related Google services associated with your Google account.
Sincerely,
Chrome Web Store Developer Support
Me
tl;dr: You're idiots.
2/11/2020 7:47 AM
This extension has been around for quite awhile. I don't obfuscate the code or do anything else that's suspicious. It's certainly not spam. The whole thing is open source and available for anyone to pick apart.
I took the time to remove the activeTab permission, which you were complaining about before. Now you're rejecting it for a completely different reason. What in the world is really going on? Do you have an interest in Twitter, and approving this extension is now some conflict of interest for Google?
At this point, I'm flummoxed. It's got a description, screenshots, icons, blah blah blah, so the only thing left is it "appears to be suspicious". What do you do with that? Okay, the code ain't the prettiest, but I attempt to hide nothing whatsoever.
Google
tl;dr: Sticks and stones and all that. Let's start over again.
2/12/2020 3:07 AM
Dear Developer,
Your item, "Twitter Tamer," with ID: aflapchiclhldkgbbahbdionenmhkoed, did not comply with our Developer Program Policies and was removed from the Google Chrome Web store.
Your item did not comply with the following section of our policy:
We may remove your item if it has a blank description field, or missing icons or screenshots, and appears to be suspicious
If you'd like to re-submit your item, please make the appropriate changes to the item so that it complies with our policies, then re-publish it in your developer dashboard. Please reply to this email for issues regarding this item removal.
*Please keep in mind that your re-submitted item will not be immediately published live in the store. All re-submitted items undergo a strict compliance review and will be re-published if the item passes review.
*Important Note
Repeated or egregious violations in the store may result in your developer account being banned from the store. This may also result in the suspension of related Google services associated with your Google account.
All re-submitted items will continue to be subject to Chrome Web Store policies and terms of service.
Thank you for your cooperation,
Google Chrome Web Store team
The only winning move is not to play
Okay, that's pretty dramatic. I won't dump Google completely, but I will start relegating them to the corner. They provide some useful services, but most of them are not novel, in no way free, and come with zero support. If only this were the first time I'd experienced that fact.
I created an extension to help others, it worked, and suddenly Google pulled the rug out. Maybe if I had a social media presence to call them out then I'd get more info... meh, probably not. For now, I've pulled the extension from the store.
One final thought. Having a few "official" stores, each tightly integrated with their own platform, seems like a Bad Idea. The perceived value is that they're keeping their respective users safe, but in reality they have their own interests... and their end-users are only a (very) small part of that.
Someone I work with noticed an, um, unexpected tag line while Notepad++ updated itself. Since Notepad++ enables its auto-updater feature by default, anyone using it - businesses, government entities, universities... middle schools - will see this screen sooner or later, front and center.
If you somehow ended up here and you're new to Notepad++, it's an open source project and, I daresay, a labor of love. It'd have to be, to stick with it for over 15 years. Since it's OSS, it's easy to see that the developer abuses the BrandingText field of the NSIS installer to inject quotes during setup, which other apps use for reasonable messages like the app name or a website URL.
In fact, the developer really likes quotes, and you can read them all here. AFAIK, the only place they're used is as an easter egg. Just type the string in the TEXT portion of a quote, highlight it, and hit F1. Some of them are nsfw, but at least it's highly unlikely most people will stumble on it.
I like Notepad++. It opens quickly (surprising, given that the "Husband is not an ATM machine" text in the above gif is yet more easter egg code), and it's got this really killer "find in files" feature that I swear works faster than a text search in Windows Explorer. And although VSCode is rocketing in popularity among developers, I'd wager far, far more people are using Notepad++ in universities and the like.
And that's the problem. A lot of people place their trust in Notepad++. It's a proven, stable, powerful, extensible app. It came out the same year as MySpace, predates Sublime (and really predates Atom), but it's still actively developed, popular, and trusted by businesses and schools alike. I wish the developer took it more seriously.
Sure, the easy retort would be to say that you can't protect kids from everything, and that businesses should be worried about more important things. But there's a certain professionalism that I'd expect to come from pride in a product that's just this good, and I'm surprised the author doesn't seem to get that.
Life is full of storms, everything from light showers to squalls. Little ones, big ones. Storms we create, storms we're swept up in. Some we're ready for, others that catch us by surprise, forcing us to refocus.. to reconsider what's really important.
A storm never lasts forever, even though it can feel like it as days stretch into weeks and months. Eventually, there's always a calm, in one form or another, after the storm passes. The weary relief of recovering from a poor financial decision, or the quiet mourning of a loved one passing. The joy of seeing that first little smile after weeks of sleepless nights, or the triumph of meeting a challenge beyond your ability... and finding it wasn't.
We can't stop most storms, only decide how to weather them. They change us, but a big part of what that changes looks like depends on how we got through it. You could curl up and hide, waiting for it to pass, or get angry and look for someone to blame. You could help someone else through it, or rise to a challenge and find a hidden strength inside yourself.
Some work better than others. I've tried most of them.
The storm we're in right now is bad. There's no getting around it, for sure - we're all just pushing through. But not having a game plan or some goals is the worst feeling. Even a half-baked solution can be better than nothing, because if we can't at least see a little light at the end of the tunnel, it's tough to have hope.
For my part, here's what I've been trying to do.
Take walks. Smile at anyone you pass. We're in this storm together, all of us. The walls around us can feel like a prison that's keeping us trapped inside.
Realize your strength. Think about the storms you've been through in your life. You survived them before, and you will again.
Redirect your energy. Did excessive worrying help last time? Could that energy have been used more productively? Think about what you want to change in your approach this time.
Tackle a project that scares you. I changed the brakes on my van the other day, and yeah it scared me a bit. But I figured it out, they work great, and it gave me a little feeling of control at a time when so much feels out of my control.
Lean into the storm. Hoping a storm will pass has set me back more than once. Don't make things easy in the short term by selling out your future self.
Be thankful for opportunities. Don't feel guilty if you get a break. Help comes from unexpected places sometimes. Go with it, and pay it forward when you can.
And you? What will you do with the time you have, while we're all waiting for this storm to pass? It's in our human nature, to survive and thrive.
Our manager organized a book club at work, and we're currently running through The Pragmatic Programmer - the original, not the 2nd edition published last Fall. If anyone is reading that, I'd love to know if it really updates things for modern programming and whether it seems necessary. The original seems pretty timeless.
So yesterday was my turn to present, listing out highlights from part of this week's reading (chapter 5), sharing some thoughts, and hopefully spurring some conversation. The authors start by talking about the Law of Demeter, but they don't explain it very well, nor do they call it by its much more self-explanatory name, the Principle of Least Knowledge.
The Principle of Least Knowledge
I like this name a lot more. I've no idea who Demeter was, or why he was making laws. And while there seems to be a set of rules to follow, I think the spirit of the thing leaves it open to interpretation based on individual circumstances.
Basically, it's about classes (modules, libraries, whatever) not exposing more about themselves than needed for other classes to use them. The term the authors use is writing "shy" code, in that a piece of code shouldn't interact more than it has to, and shouldn't let other bits of code see more than they have to.
I found a great example in an article written by David Bock, called The Paperboy, the Wallet, and the Law of Demeter. He presents a fictional story, where a paperboy needs to collect money from one of his customers, and he represents the process in code with something kinda like this, which I think is something most of us have seen.
var paid = new Customer().GetWallet().GetPayment();
The problem is that, in real life, would the paperboy really grab the customer's wallet and get money from it? Why doesn't the customer just hand the money over, which in code might mean the Customer class has a GetPayment method that hides the fact that internally there's a wallet at all. Later on, if the wallet is replaced with piggy bank, the paperboy doesn't know or care... he still gets paid!
Celebrate good times, come on!
All that stuff I said above was a generalization of David's, so I highly recommend reading his article if you want to learn more. Since you're here anyway, I'll throw my own example into the ring. Sometimes we need to see something from several slightly different angles before it clicks.
Imagine you're at a company, working on an application that all the employees use. It's got financial tools built in, and sales tools too; you can administer users and permissions, and run all manner of reports. This is far more common than you might realize, at least for companies with a few hundred employees.
A new request comes in - employees feel underappreciated, so management wants a report of anniversaries for the upcoming week, and new features that let them order a cake. And send an email. Maybe at the same time. Hey, they care but they've got other stuff to do too.
The first thing you do is dig up the Employee class, because it's got to exist somewhere in the codebase... ah, there it is, with the usual fields attributed to an employee...
public class Employee
{
public string FirstName { get; set; }
public string LastName { get; set; }
public string SSN { get; set; }
public decimal Salary { get; set; }
public DateTime HireDate { get; set; }
public DateTime? TerminationDate { get; set; }
public bool IsActive { get { return !TerminationDate.HasValue; } }
}
Now we need a Celebration class, to store logic for properly celeberating them employees' anniversaries and whatnot.
public class Celebration
{
public Employee Employee { get; private set; }
public Celebration(int empId)
{
// somehow we load the employee's data
Employee = dbContext.Students.Get(empId);
}
public void PurchaseCake()
{
// order a costco cake
}
public void PurchaseDeluxeCake()
{
// order a dairyqueen icecream cake
}
public void SendCard()
{
// fire off a hallmark card
}
}
Since we've made the instance of Employee public, it'll make things really easy for us to test certain conditions when it comes time to purchase those treats and send all that paper.
var celebrate = new Celebration(1234);
if (celebrate.Employee.IsActive
&& celebrate.Employee.HireDate.Date == DateTime.Now.Date)
{
if (celebrate.Employee.HireDate.Year + 9 < DateTime.Now.Year)
celebrate.PurchaseDeluxeCake(); // 10 years gets you the big cake
else if (celebrate.Employee.HireDate.Year < DateTime.Now.Year)
celebrate.PurchaseCake();
else
return;
celebrate.SendCard();
}
But wait a sec. Why does whatever piece of code that's checking for celebrations need to have access to the Employee class? Say this weren't code, and a manager needed to check an employee's record manually to view their hire date. Say someday all this gets offloaded to someone other than a manager, like the newly-formed party-planning committee. Is it reasonable that, just to send you a card and order your cake, a person would need access to your entire employee record including salary and social security number? Noooo. No it is not.
The Principle of Least Knowledge challenges us to rethink how much access Class A has, through Class B, to Classes C, D, and E. In other words, we should hide any details about the Employee class that don't need to be exposed - even hide the fact that there's an instance of Employee in there at all.
If we make the Employee class private inside Celebration, it forces us to refactor the rest of the class so that it never makes the rest of the employee's data available. The class instantiating Celebration could presumably access employee data anyway, but the programmer behind it would have to deliberately instantiate it.
public class Celebration
{
private Employee employee;
public Celebration(int empId)
{
// somehow we load the employee's data
employee = dbContext.Students.Get(empId);
}
public bool IsEmployeeAnniversary()
{
return employee.IsActive
&& employee.HireDate.Date < DateTime.Now.Date;
}
public void PurchaseCake()
{
if (employee.HireDate.Year + 9 < DateTime.Now.Year)
// send for a dairyqueen cake
else
// send for a costco cake
}
public void SendCard()
{
// fire off a hallmark card
}
}
This has loads of positive effects on the codebase, including:
Simplifying the logic in the caller, which no longer has to figure out how to decide if it's the employee's anniversary, just call methods and let another class do the work.
If the same code as below is called anywhere else, then the above changes DRY up the code base too, keeping the logic in one place.
And if the logic inside the Celebration code changes - maybe some other criteria goes into determining an anniversary, or being at the company 20 years gets you a Cheesecake Factory cake - then anything else in the codebase that happens to run code like the code below won't need to be touched. Nice!
var celebrate = new Celebration(1234);
if (celebrate.IsEmployeeAnniversary())
{
celebrate.PurchaseCake();
celebrate.SendCard();
}
Thanks Demeter, for your useful laws. I owe you a cake and a card.
The best thing about web design in the 90's - other than Netscape 2.0 badges, trailing mouse cursors, and blinking marquees - was that anyone could do it and look as professional as anyone else. Those were simpler times, when CSS and JavaScript were just born, we didn't have a hundred competing frameworks, and literally anyone could jump on the web and toss up a static page or ten.
If you have time to kill (and who doesn't these days?) check out the Wayback Machine for some of the best the 90's had to offer, including these quaint "corporate" sites that your gram could've made. Keep a sharp eye, and you might witness some of the elegant tools from a more civilized age.
Dell
I remember visiting Dell as a teen, configuring some outrageous machine with maxed out everything - a gig of RAM, a DVD/CD writer combo, 4 GB hdd (FOUR. GIGS.) - just to see what the total price would be, then dream about being able to buy it. I purchased my first flatscreen monitor from Dell.. it was an exciting day when I could dump my CRT monitor.
Check out Dell's site from 1996. The pastels! The liberal use of images that comprised 95% of the page! And what about those thick table borders!
Wait a sec... Those aren't table borders - they're one of the most ubiquitous tools in any 90's web designer's toolbelt, the 1x1 transparent dot.gif! With a single image stretched to any height or width, you could create borders and position elements around the screen. It's a mystery why we ever needed CSS.
Movin' on, check out State Farm's site from 1996. Love the background that looks like a manila folder viewed on an old tube TV. Love how they were upfront with visitors about the next update too. Ain't no one gonna bother firing up Adobe PageMill, updating the page, and uploading it with CuteFTP over the holidays. I'm sure everyone was waiting with bated breath.
AT&T
Next up, AT&T. You can't see it, but there was a ticker applet right above that center image. Tragically, it wasn't archived. Speaking of which, what is going on in that image? Is that a missing child and the other guy is sobbing? If you squint your eyes, it almost looks like the guy on the right is wearing blue pants and a black shirt, and the guy on the left is carrying him. Anyway.
What we've also got is our first example of an image map, where the time-constrained 90's web developer could slap a single image up (for the entire page if desired), then split it into dozens of clickable areas. Why did we ever need the rest of the HTML spec? Give me img, map, and area tags, and I'll take over the world.
A feast for the eyes. Back in the mid 90's, McDonald's apparently let children design their website with Windows Paint and Broderbund Print Shop.
Don't click on the kids or the adults.. or anything! I tried to warn you...
Freaking Pennywise. (Help!)
Wendy's
Back in the 90s, Wendy's owner Dave was living in a, um, what does that look like to you? The mansion from Clue maybe. Doesn't look like any Wendy's I've ever seen, but apparently those square patties made him enough money to paint his house gold.
Lots of pastels. I think it really was the Clue mansion, lol.
While you're at it, check out Burger King's too.. it's just a few images. I really want to know who M Piernick was!
<!-- Burger King updated M. Piernick -->
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<meta name="description" content="The Official World Wide Web Site of Burger King Corporation, Miami, Florida.">
<meta name="keywords" content="burger king, burger king corporation,whopper,have it your way,burger king kids club,get your burgers worth,burgers,king,miami">
<meta name="FORMATTER" content="Microsoft FrontPage 2.0">
<meta name="GENERATOR" content="Microsoft FrontPage 2.0">
<title>Welcome to the Official Home Page of Burger King Corporation</title>
</head>
CVS
There's not too much to say about CVS, except the little old lady who designed all the other websites is featured in the corner. Note the sweet shadow effect that we'd use CSS for now. But that ain't CSS.
Yep, that's a 1024px wide x 1px tall gif. In the 90's, there was no problem that couldn't be solved with just one more gif. They were decades ahead of their time too, ready to handle any resolution that might ever be supported. I mean, not the actual content, but the background was all set.
Lowes
Lowe's knows how to design a website! They'd been on the web for a year, and had a contest to win a 27" color tv! WOW! (Goodwill won't even take those now... I tried a few years ago.)
Home(r) Depot
If you're a Home Depot fan and laughing at Lowe's pastel buttons, allow me to rain on your parade - HD wasn't any better. Homer?
Given how big the Simpsons were in the 90's, and how incompetent its lead character of the same name was, it seems like an odd choice.
MetLife
MetLife was celebrating a year online too, just like Lowe's. What an exciting time to be online, celebrating the simple fact that we managed to host a few static pages. Just amazing.
The White House
Last but not least, and not actually a corporation, The White House site is worth a peek. Love the background. It's actually easier on the eyes than most of the other stuff I found, but then they're not trying to grab your attention with bright colors and creepy clowns so they've got that going for them.
The 90's really were the golden era of web design.. as long as you're a bit liberal on your definitions of gold. And era. And design.
If you want to have a little fun too (the bar is low during a pandemic), check out the Fortune 500 and Wayback Machine sites, and see if you can find some goofy sites too. And if you find any good ones, let me know. We could all use a smile. 😂
Ask most homeowners whether it's more fun to add a new deck or restain an old one, install a new kitchen or revamp the outdated one one, lay down new carpet or shampoo the old, buy a new car or pay for a 50k mile checkup, and the answer will nearly always be the first one.. rarely the second.
The "new" captivates us, engages our imagination, incites feelings of discovery and opportunities. It gives us a chance to step back, take a deep breath, and plunge into something different and exciting. Maybe we need that to recalibrate ourselves, to try harder the second (or third, or fourth) time around.
It's also in part a false hope - a fool's hope - that none of the "old" concerns will ever plague us again. We'll stain the deck every year so it doesn't rot, wash the car every day so it doesn't rust, and wipe down the kitchen every day so it looks as fresh as the day it was installed. We're dreamers.
But we know deep down that every new home will become old, every kitchen outdated, every car rusted, and we will find ourselves once again in the (boring, drab, but oh so vital) role of maintainer. Or are we just scared or too impatient to slow down and take stock of what we have, what already works, and admit that it's worth keeping around in some shape or form.
Maintenance is...
appreciating a thing for what it is, but seeing potential in it too
recognizing a thing was (and is) good, and worthy of improvement
accepting that some work is important, even if it rarely earns praise
acknowledging the years of (physical and mental) effort poured into a thing
realizing the old can be sinewy and strong in need a good polishing, while the new might be shiny plating over something that will crumble
I find myself in the position of maintainer often, and have for many years - whether my house, my car, or the decades-old applications I've worked on for various companies. If you haven't yet, you will too. Sometimes we get the opportunity to tackle a novel problem or a new task, and that's a great feeling.
But the next time we put on the hat of the maintainer, let's try to keep in mind that it's the role that requires (and creates) appreciation and wisdom, as well as a discerning eye and a clever mind. It's where a deeper growth occurs.
One of the more common things we read about technology these days is just how disconnected all this connectedness is making us. I bet a good psychologist could shed light on all the complex reasons for that, but I'd also bet it's mostly a fear of missing out. Of being out of the loop.. whatever loop we've concocted in our own heads that we think we're part of.
There's this brief moment of escapism, and a feeling that we're part of "it". Of whatever, or everything.. or something. It's like we jump on a giant raft, spinning down a turbulent river with a bunch of people we don't really know (or even like), screaming about politics, virtue signaling, promoting ourselves... saying whatever stupid thing pops into our heads so we're not forgotten. Lately, we've been fallingoff the raft quite a bit.
But before you take to atwitter or facepalm to lament the state of the current generation and "these times", realize that it started a long time ago. There's nothing new under the sun, not really.
Nearly a century ago, Norman Rockwell captured (as usual) an aspect of human nature that's probably been around since the first time a caveman found some gossip etched into a cave wall or chiseled a selfie. Like the man behind the newspaper, most of what we read or watch or post isn't as significant as what's going on around us, and after an hour or two most of us can't even recall the whole trip anyway. It's like cheetos for the brain.
And it's not jumping off the raft that scares us, but the fear that no one will even notice we're gone. Isn't it parodoxical, that we can be plugged into everything, yet still feel alone and unheard, which in turn causes those around us to feel alone and unheard too? Shallow connections that deprive us of deep connections.
For my part, I dumped social media a couple years ago. Eventually, I reduced my news consumption to local sites and those with focused interests, like technology or religion, but I generally avoid the click-baity national sites (msn, fox, etc). Last year, I started making a more concerted effort to physically move my laptop or phone aside, and close the lid or turn off the display, when my wife came over to talk.
Nothing works all the time. I still read something, get fired up, and want to join in the great cacophony. Other times I get caught up in an article, and find myself sitting behind the proverbial newspaper with someone right next to me trying to have a conversation. Sometimes I come to my senses. Sometimes I realize I've got a far ways to go. I'm a work in progress.
What does all this mean for you? Maybe nothing. Or maybe pin a message in your feed that says you're taking the next 2 weeks off, and jump off the raft for awhile. Don't worry, it'll be right where you left it.
When it comes to writing software and deciding where to store files for your users, Windows makes it easy by setting certain areas of the system aside, and grouping them into two general categories.
Files your app requires to run, or creates while running (i.e. logs), should go in program files, application data, etc. Keep them away from the user - they don't want them, and you don't want them to notice them.
Files a user creates with your app (i.e. a spreadsheet in Excel) should go in my documents, music, desktop, etc. Keep them near and dear to the user, so they can find them again, back them up, sync them using Dropbox, share them, whatever.
These special folders aren't necessarily a specific location. They vary by version of Windows, and users can even change their location manually. But that doesn't matter, because Windows abstracts away the exact location to make life easier for developers, and you should totally take advantage of that.
Why's it matter?
Here's what my My Documents currently looks like - loads of stuff I don't care about and shouldn't be aware of on a daily basis. Amazon is storing encrypted ebook files that are useless outside their app. ShareX stores log files and plugins, Microsoft some out-of-the-box templates, and Zoom.. well... an empty directory. 🙄
It sucks. It's like I've got this nice little area that's supposed to be just mine, but every plumber, electrician, and hvac specialist decided to just run everything through the living room. There's wires dangling from the mantle, plumbing running in front of the tv screen, duct work across the sofa. Crap everywhere. Thanks.
If I want to sync My Documents between several machines, I don't need ShareX's logs on both. I can install the Kindle app on multiple machines to download books - those encrypted files are worthless to me.
Well, what can a dev do? (spoiler: plenty)
Windows has had this concept of special folders going back to Windows 95. That's right, like 25 years ago! You can view the folders in the registry editor, but don't use them from there. Seriously, it's a long and sad story apparently. On a side note, let no one say Microsoft takes backwards compatibility lightly.
The keen observer might've noticed some bright red text that totally stood out from everything else in Raymond Chen's long, sad story - those are (outdated) Windows API calls for getting special folders. The new hotness is SHGetKnownFolderPath, although SHGetFolderPath works as well (it simply calls the former).
What you can do in C++
If you're using c++, here's something I cobbled together. This might be ugly for c++.. or it might be ugly just because it's c++. It uses the SHGetKnownFolderPath function directly.
#include <windows.h>
#include <iostream>
#include <shlobj.h>
using namespace std;
#pragma comment(lib, "shell32.lib")
int main() {
PWSTR path = NULL;
HRESULT result = SHGetKnownFolderPath(FOLDERID_Documents, 0, NULL, &path);
if (result != S_OK)
std::cout << "Error: " << result << "\n";
else
wprintf(L"%ls\n", path);
cin.get(); // pause to view result
return 0;
}
// output: C:\Users\Grant\Documents
What you can do in C#
The .NET Framework makes things even easier. I mean, it's so easy one wonders why an app like ShareX that appears to be written in C# would be storing log files in my living room documents folder at all. 😠
using System
using static System.Environment;
namespace GetKnownFolder
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(GetFolderPath(SpecialFolder.MyDocuments));
Console.ReadLine();
}
}
}
// output: C:\Users\Grant\Documents
If you investigatefurther, .NET is actually wrapping the API call for us. 👍
Okay, I don't know Python that well. This might only work for Python 2, plus the CSIDL values have been supplanted by something newer (although, you know.. backwards compatibility and all).
There are options. Mostly quite easy ones.
So, let's recap and drive the point home, because I've been subtle up to now. If you're using a language from the last couple of decades, to write something for Windows that needs access to the file system, more likely than not there's a way to access the special system folders.
Please look into it. Please store anything your app needs in something called application data, or local data, or local application data, or really anything with "application" or "program" in the name. I know "My Documents" might sound like something that belongs to you, but it really doesn't. It's mine. Mine. ALL MINE!