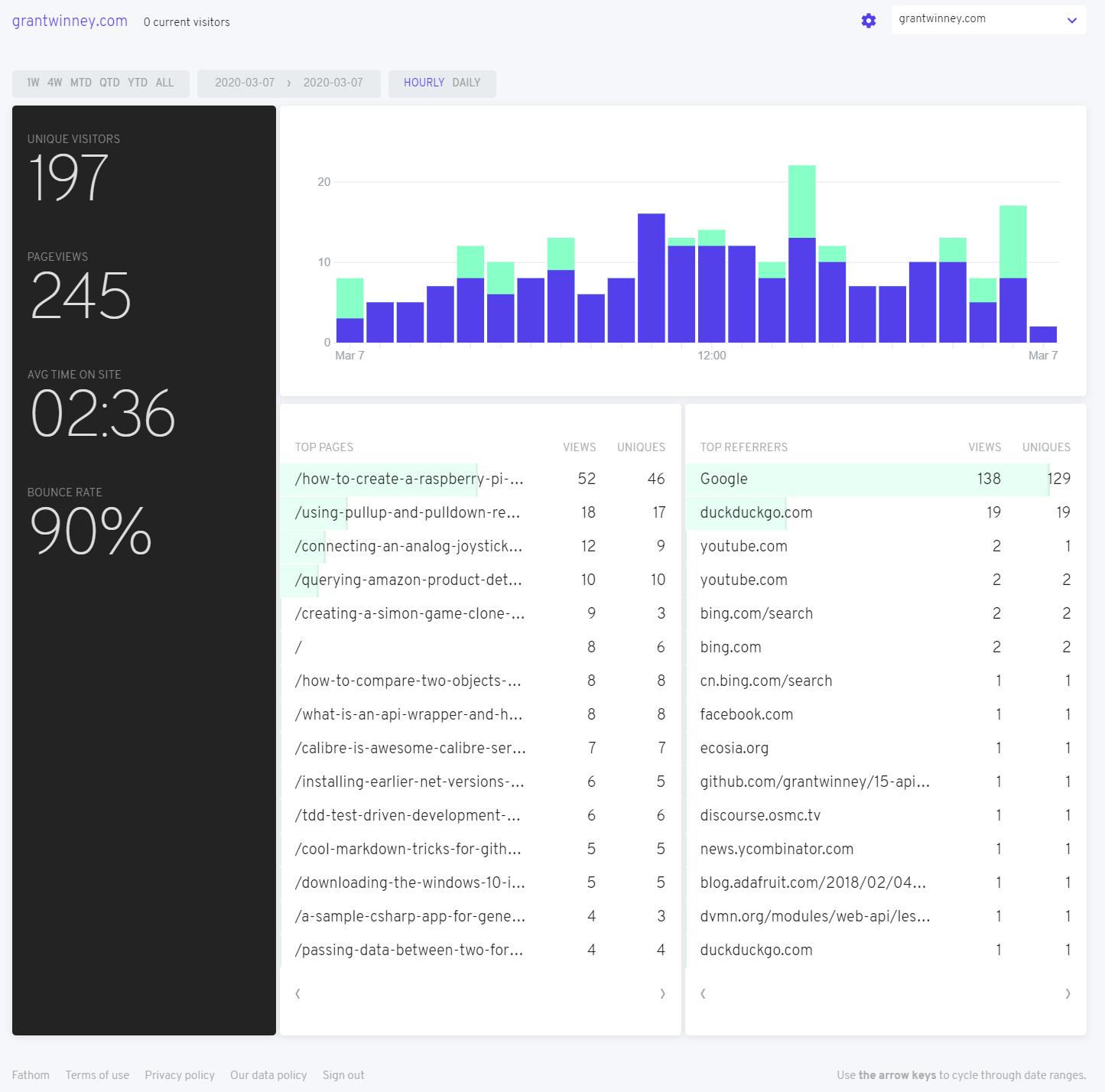
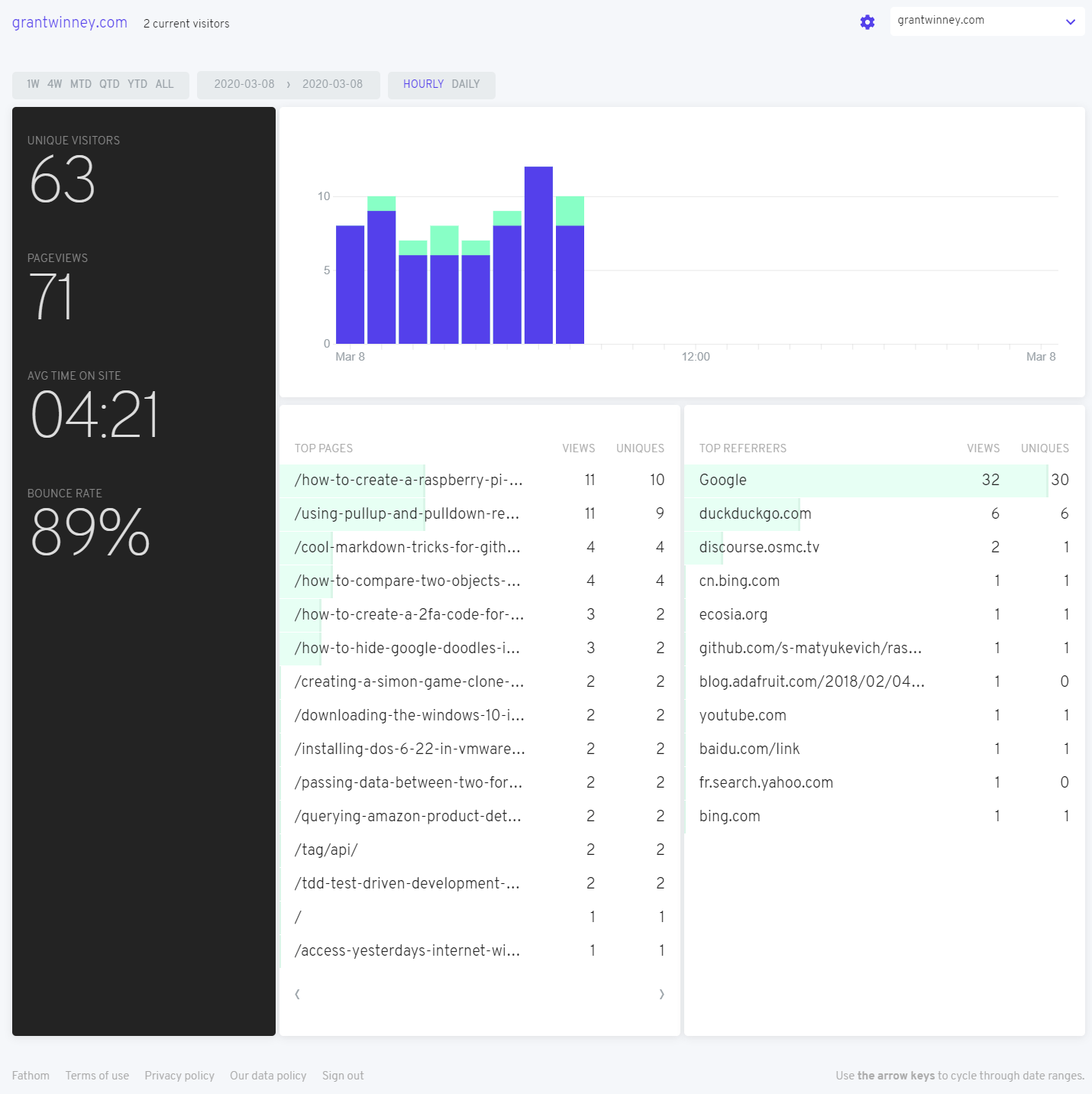
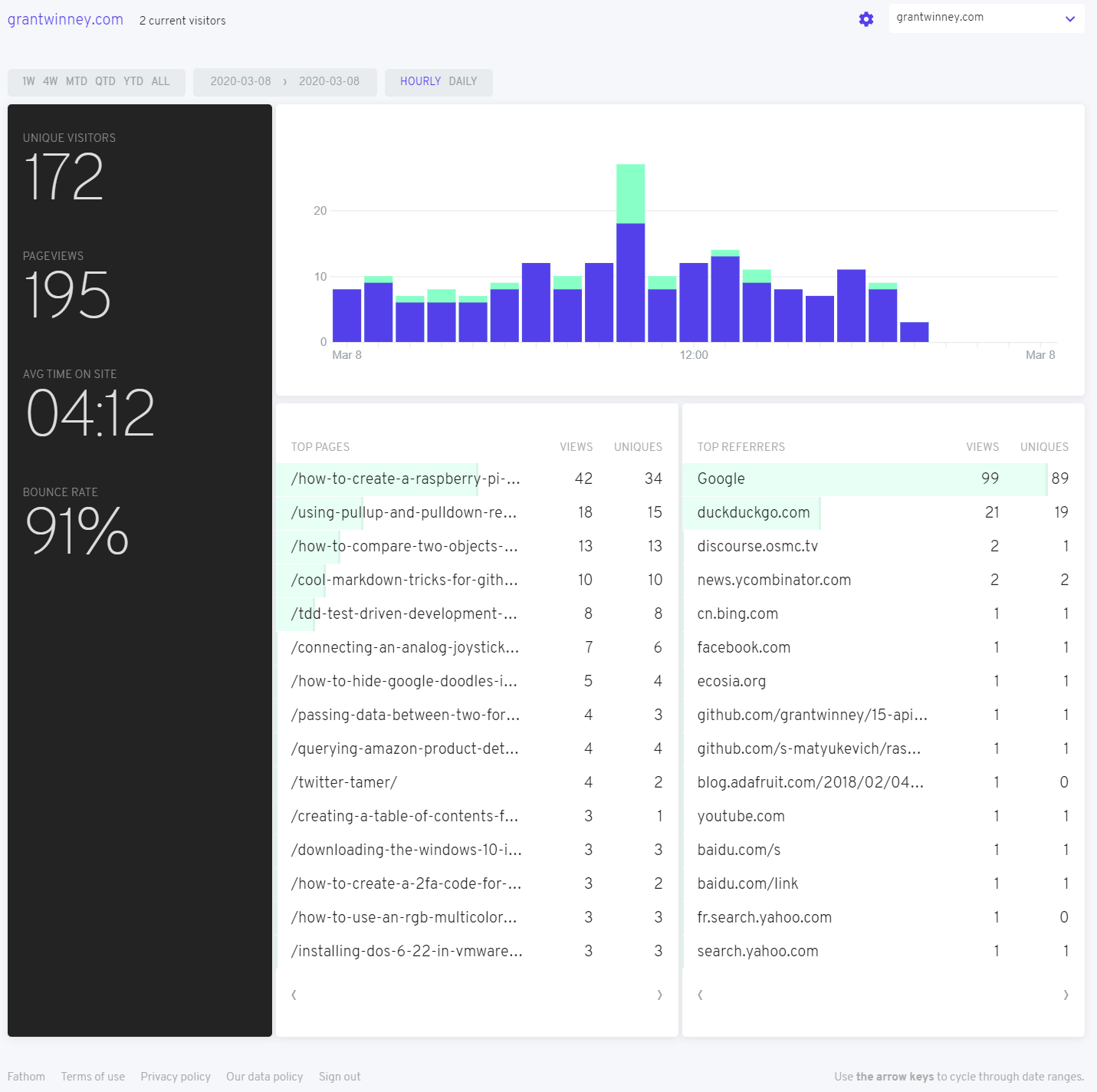
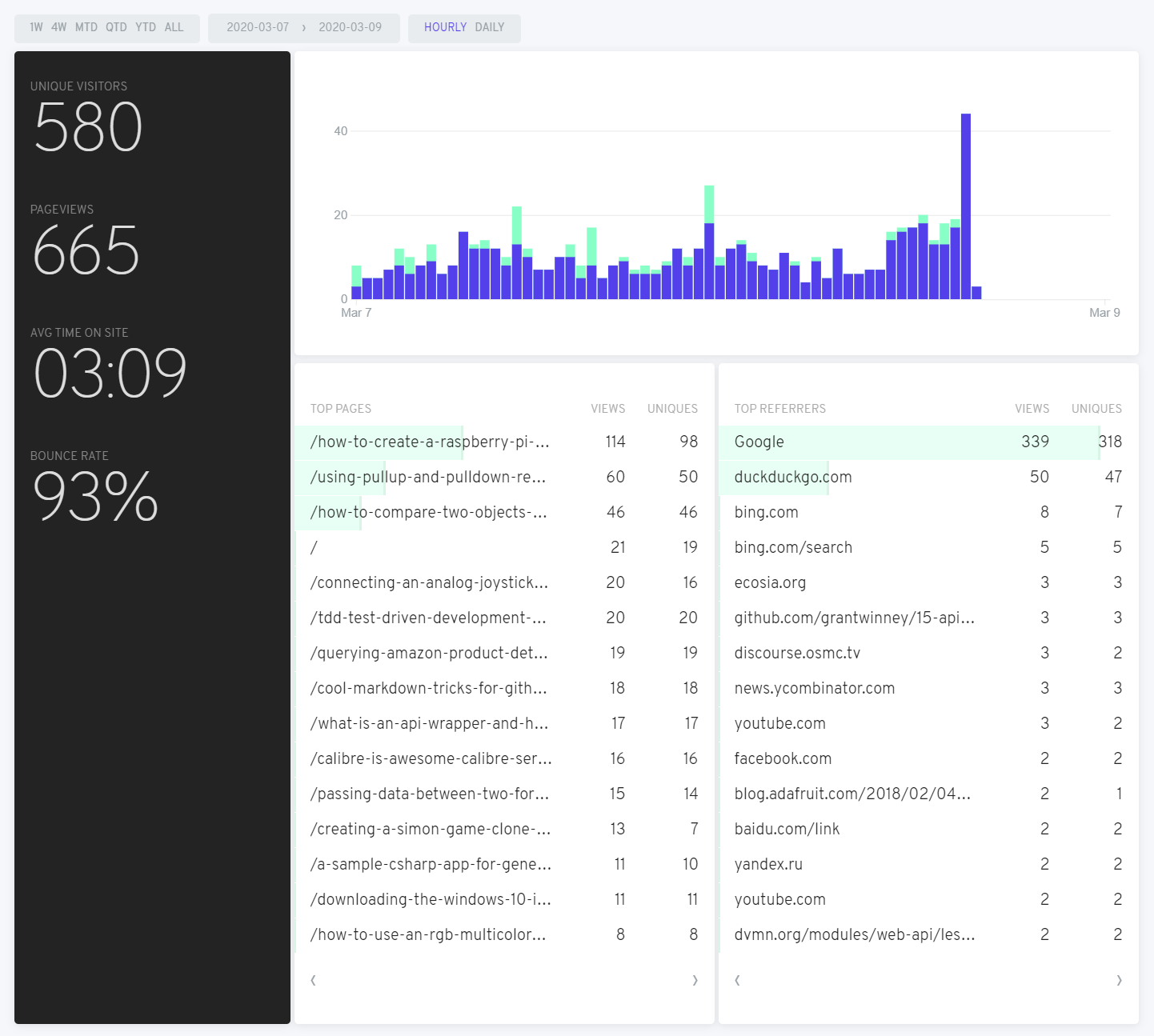
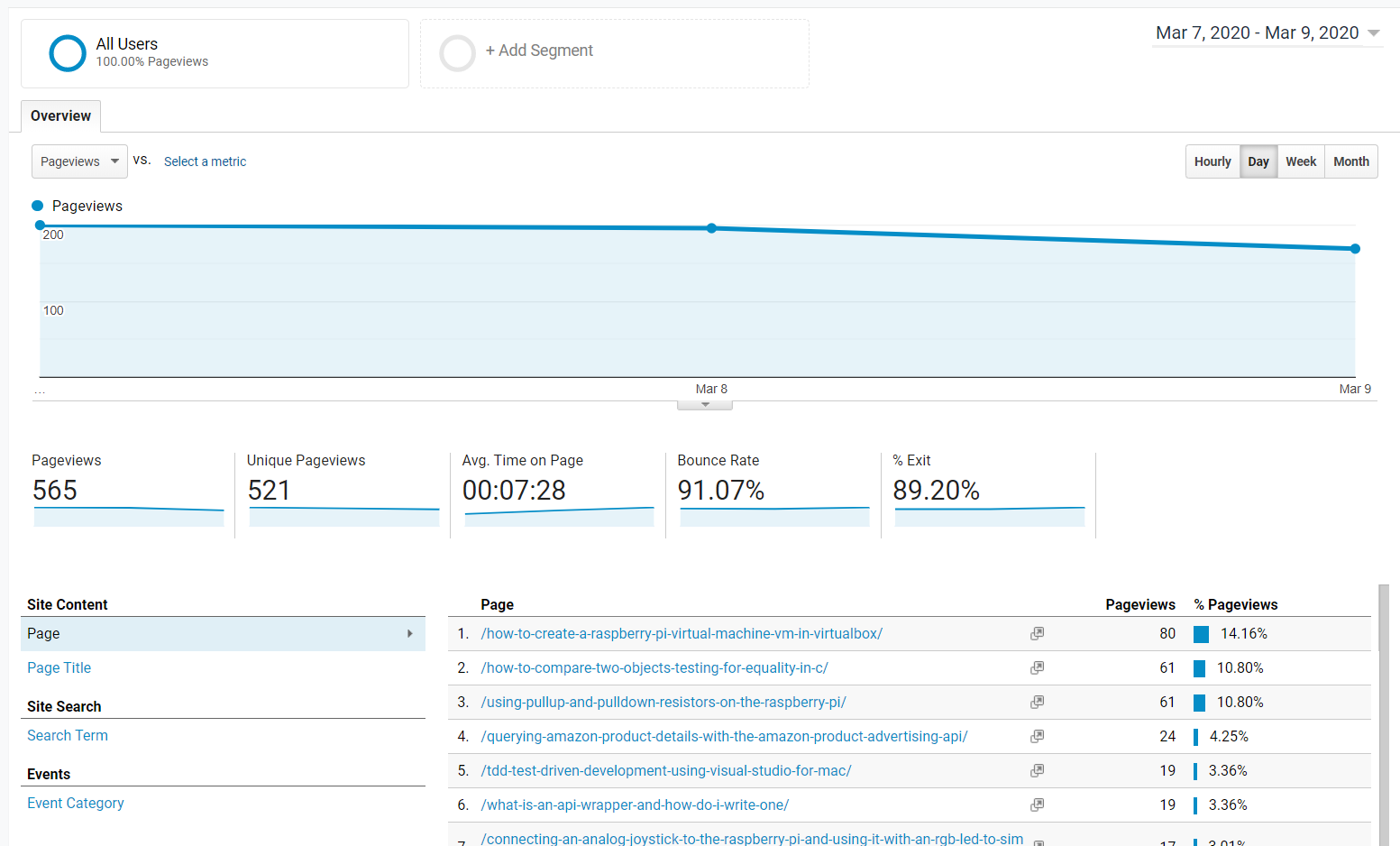
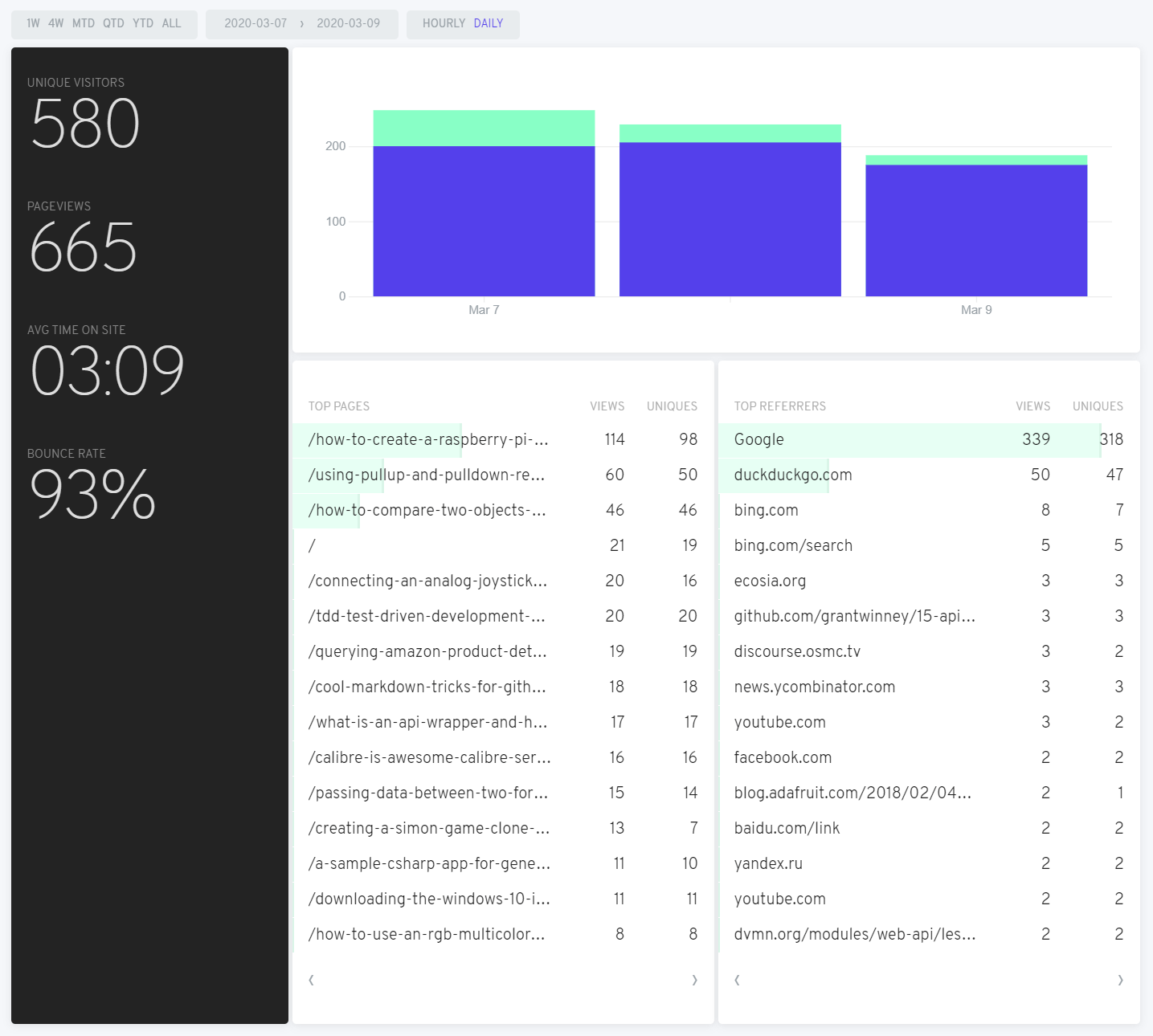
StackOverflow sees quite a few threads deleted, usually for good reasons. Among the stinkers, though, lies the occasionally useful or otherwise interesting one, deleted by some pedantic nitpicker - so I resurrect them. 👻
Note: Because these threads are older, info may be outdated and links may be dead. Feel free to contact me, but I may not update them... this is an archive after all.
What is your most useful SQL trick to avoid writing more code?
Question asked by EvilTeach
I am intending this to be an entry which is a resource for anyone to find out about aspects of SQL that they may have not run into yet, so that the ideas can be stolen and used in their own programming. With that in mind...
What SQL tricks have you personally used, that made it possible for you to do less actual real world programming to get things done?
[EDIT]
A fruitful area of discussion would be specific techniques that allow you to do operations on the database side, that make it unnecessary to pull the data back to the program, then update/insert it back to the database.
[EDIT]
I recommend that you flesh out your answer where possible to make it easy for the reader to understand the value that your technique provides. Visual examples work wonders. The winning answer will have good examples.
My thanks to everyone who shared an idea with the rest of us.
Comments
Another way to phrase this question is "what good programming practices have you disregarded to spill logic between concerns and make miserable the poor chap who has to come after you and try to make changes?" Not that pragmatism is a bad thing :) – Rex M Jan 28 '09 at 19:18
Answer by Rad
This statement can save you hours and hours of programming
insert into ... select ... from
For example:
INSERT INTO CurrentEmployee SELECT * FROM Employee WHERE FireDate IS NULL; will populate your new table with existing data. It avoids the need to do an ETL operation or use multiple insert statements to load your data.
Answer by EvilTeach
I think the most useful one that I have used, is the WITH statement.
It allows subquery reuse, which makes it possible to write with a single query invocation, what normally would be two or more invocations, and the use of a temporary table.
The with statement will create inline views, or use a temporary table as needed in Oracle.
Here is a silly example
WITH
mnssnInfo AS
(
SELECT SSN,
UPPER(LAST_NAME),
UPPER(FIRST_NAME),
TAXABLE_INCOME,
CHARITABLE_DONATIONS
FROM IRS_MASTER_FILE
WHERE STATE = 'MN' AND -- limit to Minne-so-tah
TAXABLE_INCOME > 250000 AND -- is rich
CHARITABLE_DONATIONS > 5000 -- might donate too
),
doltishApplicants AS
(
SELECT SSN, SAT_SCORE, SUBMISSION_DATE
FROM COLLEGE_ADMISSIONS
WHERE SAT_SCORE < 100 -- Not as smart as some others.
),
todaysAdmissions AS
(
SELECT doltishApplicants.SSN,
TRUNC(SUBMISSION_DATE) SUBMIT_DATE,
LAST_NAME, FIRST_NAME,
TAXABLE_INCOME
FROM mnssnInfo,
doltishApplicants
WHERE mnssnInfo.SSN = doltishApplicants.SSN
)
SELECT 'Dear ' || FIRST_NAME ||
' your admission to WhatsaMattaU has been accepted.'
FROM todaysAdmissions
WHERE SUBMIT_DATE = TRUNC(SYSDATE) -- For stuff received today onlyOne of the other things I like about it, is that this form allows you to separate the filtering from the joining. As a result, you can frequently copy out the subqueries, and execute them stand alone to view the result set associated with them.
Answer by GBa (Jan 28, 2009)
Writing "where 1=1...." that way you don't have to keep track of where to put an AND into the statement you're generating.
Answer by Eric Johnson
Copy a table without copying the data:
select * into new_table from old_table where 1=0OR
SELECT TOP(0) * INTO NEW_TABLE FROM OLD_TABLEAnswer by Mark Harrison
My old office-mate was an extreme SQL enthusiast. So whenever I would complain "Oh dear, this SQL stuff is so hard, I don't think there's any way to solve this in SQL, I'd better just loop over the data in C++, blah blah," he would jump in and do it for me.
Answer by geofftnz
Use Excel to generate SQL. This is especially useful when someone emails you a spreadsheet full of rubbish with a request to "update the system" with their modifications.
A B C
1 BlahID Value SQL Generation
2 176 12.76 ="UPDATE Blah SET somecolumn=" & B2 & " WHERE BlahID=" & A2
3 177 10.11 ="UPDATE Blah SET somecolumn=" & B3 & " WHERE BlahID=" & A3
4 178 9.57 ="UPDATE Blah SET somecolumn=" & B4 & " WHERE BlahID=" & A4You do need to be careful though because people will have a column for something like UnitPrice and have 999 valid entries and one containing "3 bucks 99 cents".
Also "I have highlighted set A in yellow and set B in green. Put the green ones in the database." grrr.
EDIT: Here's what I actually use for Excel->SQL. I've got a couple of VBA functions that sit in an XLA file that's loaded by Excel on startup. Apologies for any bugs - it's a quick dirty hack that's nonetheless saved me a bucketload of time over the past few years.
Public Function SQL_Insert(tablename As String, columnheader As Range, columntypes As Range, datarow As Range) As String
Dim sSQL As String
Dim scan As Range
Dim i As Integer
Dim t As String
Dim v As Variant
sSQL = "insert into " & tablename & "("
i = 0
For Each scan In columnheader.Cells
If i > 0 Then sSQL = sSQL & ","
sSQL = sSQL & scan.Value
i = i + 1
Next
sSQL = sSQL & ") values("
For i = 1 To datarow.Columns.Count
If i > 1 Then sSQL = sSQL & ","
If LCase(datarow.Cells(1, i).Value) = "null" Then
sSQL = sSQL & "null"
Else
t = Left(columntypes.Cells(1, i).Value, 1)
Select Case t
Case "n": sSQL = sSQL & datarow.Cells(1, i).Value
Case "t": sSQL = sSQL & "'" & Replace(datarow.Cells(1, i).Value, "'", "''") & "'"
Case "d": sSQL = sSQL & "'" & Excel.WorksheetFunction.Text(datarow.Cells(1, i).Value, "dd-mmm-yyyy") & "'"
Case "x": sSQL = sSQL & datarow.Cells(1, i).Value
End Select
End If
Next
sSQL = sSQL & ")"
SQL_Insert = sSQL
End Function
Public Function SQL_CreateTable(tablename As String, columnname As Range, columntypes As Range) As String
Dim sSQL As String
sSQL = "create table " & tablename & "("
Dim scan As Range
Dim i As Integer
Dim t As String
For i = 1 To columnname.Columns.Count
If i > 1 Then sSQL = sSQL & ","
t = columntypes.Cells(1, i).Value
sSQL = sSQL & columnname.Cells(1, i).Value & " " & Right(t, Len(t) - 2)
Next
sSQL = sSQL & ")"
SQL_CreateTable = sSQL
End FunctionThe way to use them is to add an extra row to your spreadsheet to specify column types. The format of this row is "x sqltype" where x is the type of data (t = text, n = numeric, d = datetime) and sqltype is the type of the column for the CREATE TABLE call. When using the functions in forumulas, put dollar signs before the row references to lock them so they dont change when doing a fill-down.
eg:
Name DateOfBirth PiesPerDay SQL
t varchar(50) d datetime n int =SQL_CreateTable("#tmpPies",A1:C1,A2:C2)
Dave 15/08/1979 3 =sql_insert("#tmpPies",A$1:C$1,A$2:C$2,A3:C3)
Bob 9/03/1981 4 =sql_insert("#tmpPies",A$1:C$1,A$2:C$2,A4:C4)
Lisa 16/09/1986 1 =sql_insert("#tmpPies",A$1:C$1,A$2:C$2,A5:C5)Which gives you:
create table #tmpPies(Name varchar(50),DateOfBirth datetime,PiesPerDay int)
insert into #tmpPies(Name,DateOfBirth,PiesPerDay) values('Dave','15-Aug-1979',3)
insert into #tmpPies(Name,DateOfBirth,PiesPerDay) values('Bob','09-Mar-1981',4)
insert into #tmpPies(Name,DateOfBirth,PiesPerDay) values('Lisa','16-Sep-1986',1)Answer by Ric Tokyo
I personally use the CASE statement a lot. Here are some links on it, but I also suggest googling.
Quick example:
SELECT FirstName, LastName, Salary, DOB, CASE Gender
WHEN 'M' THEN 'Male'
WHEN 'F' THEN 'Female'
END
FROM EmployeesAnswer by Patrick Cuff
I like to use SQL to generate more SQL.
For example, I needed a query to count the number of items across specific categories, where each category is stored in its own table. I used the the following query against the master category table to generate the queries I needed (this is for Oracle):
select 'select '
|| chr(39) || trim(cd.authority) || chr(39) || ', '
|| chr(39) || trim(category) || chr(39) || ', '
|| 'count (*) from ' || trim(table_name) || ';'
from category_table_name ctn
, category_definition cd
where ctn.category_id = cd.category_id
and cd.authority = 'DEFAULT'
and category in ( 'CATEGORY 1'
, 'CATEGORY 2'
...
, 'CATEGORY N'
)
order by cd.authority
, category;This generated a file of SELECT queries that I could then run:
select 'DEFAULT', 'CATEGORY 1', count (*) from TABLE1;
select 'DEFAULT', 'CATEGORY 2', count (*) from TABLE4;
...
select 'DEFAULT', 'CATEGORY N', count (*) from TABLE921; Answer by Powerlord
Besides normalization (the obvious one), setting my foreign key on update and on delete clauses correctly saves me time, particularly using ON DELETE SET NULL and ON UPDATE CASCADE
Answer by JosephStyons (Jan 28, 2009)
I have found it very useful to interact with the database through views, which can be adjusted without any changes to code (except, of course SQL code).
Answer by Terrapin
When developing pages in ASP.NET that need to utilize a GridView control, I like to craft the query with user-friendly field aliases. That way, I can simply set the GridView.AutoGenerateColumns property to true, and not spend time matching HeaderText properties to columns.
select
MyDateCol 'The Date',
MyUserNameCol 'User name'
from MyTableAnswer by Paul Chernoch (Jun 25, 2009)
Date arithmetic and processing drives me crazy. I got this idea from the Data Warehousing Toolkit by Ralph Kimball.
Create a table called CALENDAR that has one record for each day going back as far as you need to go, say from 1900 to 2100. Then index it by several columns - say the day number, day of week, month, year, etc. Add these columns:
ID
DATE
DAY_OF_YEAR
DAY_OF_WEEK
DAY_OF_WEEK_NAME
MONTH
MONTH_NAME
IS_WEEKEND
IS_HOLIDAY
YEAR
QUARTER
FISCAL_YEAR
FISCAL_QUARTER
BEGINNING_OF_WEEK_YEAR
BEGINNING_OF_WEEK_ID
BEGINNING_OF_MONTH_ID
BEGINNING_OF_YEAR_ID
ADD_MONTH
etc.Add as many columns as are useful to you. What does this buy you? You can use this approach in any database and not worry about the DATE function syntax. You can find missing dates in data by using outer joins. You can define multi-national holiday schemes. You can work in fiscal and calendar years equally well. You can do ETL that converts from words to dates with ease. The host of time-series related queries that this simplifies is incredible.
Answer by Binoj Antony
In SQL Server 2005/2008 to show row numbers in a SELECT query result
SELECT ( ROW_NUMBER() OVER (ORDER BY OrderId) ) AS RowNumber,
GrandTotal, CustomerId, PurchaseDate
FROM OrdersORDER BY is a compulsory clause. The OVER() clause tells the SQL engine to sort data on the specified column (in this case OrderId) and assign numbers as per the sort results.
Answer by J. Polfer
The two biggest things I found were helpful were doing recursive queries in Oracle using the CONNECT BY syntax. This saves trying to write a tool to do the query for you. That, and using the new windowing functions to perform various calculations over groups of data.
Recursive Hierarchical Query Example (note: only works with Oracle; you can do something similar in other databases that support recursive SQL, cf. book I mention below):
Assume you have a table, testtree, in a database that manages Quality Assurance efforts for a software product you are developing, that has categories and tests attached to those categories:
CREATE TABLE testtree(
id INTEGER PRIMARY KEY,
parentid INTEGER FOREIGN KEY REFERENCES testtree(id),
categoryname STRING,
testlocation FILEPATH);
Example Data in table:
id|parentid|categoryname|testlocation
-------------------------------------
00|NULL|ROOT|NULL
01|00|Frobjit 1.0|NULL
02|01|Regression|NULL
03|02|test1 - startup tests|/src/frobjit/unit_tests/startup.test
04|02|test2 - closing tests|/src/frobjit/unit_tests/closing.test
05|02|test3 - functionality test|/src/frobjit/unit_tests/functionality.test
06|01|Functional|NULL
07|06|Master Grand Functional Test Plan|/src/frobjit/unit_tests/grand.test
08|00|Whirlgig 2.5|NULL
09|08|Functional|NULL
10|09|functional-test-1|/src/whirlgig/unit_tests/test1.test
(...)I hope you get the idea of what's going on in the above snippet. Basically, there is a tree structure being described in the above database; you have a root node, with a Frobjit 1.0 and Whirlgig 2.5 node being described beneath it, with Regression and Functional nodes beneath Frobjit, and a Functional node beneath Whirlgig, all the way down to the leaf nodes, which contain filepaths to unit tests.
Suppose you want to get the filepaths of all unit tests for Frobjit 1.0. To query on this database, use the following query in Oracle:
SELECT testlocation
FROM testtree
START WITH categoryname = 'Frobjit 1.0'
CONNECT BY PRIOR id=parentid;A good book that explains a LOT of techniques to reduce programming time is Anthony Mollinaro's SQL Cookbook.
Answer by EvilTeach (Jan 29, 2009)
In some of my older code, I issue a SELECT COUNT(*) in order to see how many rows there are, so that we can allocate enough memory to load the entire result set. Next we do a query to select the actual data.
One day it hit me.
WITH
base AS
(
SELECT COL1, COL2, COL3
FROM SOME-TABLE
WHERE SOME-CONDITION
)
SELECT COUNT(*), COL1, COL2, COL3
FROM base;That gives me the number of rows, on the first row (and all the rest).
So I can read the first row, allocate the array, then store the first row, then load the rest in a loop.
One query, doing the work that two queries did.
Answer by Michael Buen
Knowing the specifics of your RDBMS, so you can write more concise code.
- concatenate strings without using loops. MSSQL:
- something that can prevent writing loops:
declare @t varchar(1000000) -- null initially;
select @t = coalesce(@t + ', ' + name, name) from entities order by name;
print @t- alternatively:
declare @s varchar(1000000)
set @s = ''
select @s = @s + name + ', ' from entities order by name
print substring(@s,1,len(@s)-1)-
Adding an autonumber field to help ease out deleting duplicate records(leave one copy). PostgreSQL, MSSQL, MySQL:
http://mssql-to-postgresql.blogspot.com/2007/12/deleting-duplicates-in-postgresql-ms.html
-
Updating table from other table. PostgreSQL, MSSQL, MySQL:
http://mssql-to-postgresql.blogspot.com/2007/12/updates-in-postgresql-ms-sql-mysql.html
-
getting the most recent row of child table.
PostgreSQL-specific:
SELECT DISTINCT ON (c.customer_id) c.customer_id, c.customer_name, o.order_date, o.order_amount, o.order_id FROM customers c LEFT JOIN orders O ON c.customer_id = o.customer_id ORDER BY c.customer_id, o.order_date DESC, o.order_id DESC;Contrast with other RDBMS which doesn't support DISTINCT ON:
select c.customer_id, c.customer_name, o.order_date, o.order_amount, o.order_id from customers c ( select customer_id, max(order_date) as recent_date from orders group by customer_id ) x on x.customer_id = c.customer_id left join orders o on o.customer_id = c.customer_id and o.order_date = x.recent_date order by c.customer_id -
Concatenating strings on RDBMS-level(more performant) rather than on client-side:
http://www.christianmontoya.com/2007/09/14/mysql-group_concat-this-query-is-insane/
http://mssql-to-postgresql.blogspot.com/2007/12/cool-groupconcat.html
-
Leverage the mappability of boolean to integer:
MySQL-specific (boolean == int), most concise:
select entity_id, sum(score > 15) from scores group by entity_idContrast with PostgreSQL:
select entity_id, sum((score > 15)::int) from scores group by entity_idContrast with MSSQL, no first-class boolean, cannot cast to integer, need to perform extra hoops:
select entity_id, sum(case when score > 15 then 1 else 0 end) from scores group by entity_id -
Use generate_series to report gaps in autonumber or missing dates, on next version of PostgreSQL(8.4), there will be generate_series specifically for date:
select '2009-1-1'::date + n as missing_date from generate_series(0, '2009-1-31'::date - '2009-1-1'::date) as dates(n) where '2009-1-1'::date + dates.n not in (select invoice_date from invoice)
Answer by Beska
This doesn't save "programming" time, per se, but sure can save a lot of time in general, if you're looking for a particular stored proc that you don't know the name of, or trying to find all stored procs where something is being modified, etc. A quick query for SQL Server to list stored procs that have a particular string somewhere within them.
SELECT ROUTINE_NAME, ROUTINE_DEFINITION
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_DEFINITION LIKE '%foobar%'
AND ROUTINE_TYPE='PROCEDURE'Same for Oracle:
select name, text
from user_source u
where lower(u.text) like '%foobar%'
and type = 'PROCEDURE';Answer by indigo80
(Very easy trick - this post is that long only because I'm trying to fully explain what's going on. Hope you like it.)
SummaryBy passing in optional values you can have the query ignore specific WHERE clauses. This effectively makes that particular clause become a 1=1 statement. Awesome when you're not sure what optional values will be provided.
DetailsInstead of writing a lot of similar queries just for different filter combinations, just write one and exploit boolean logic. I use it a lot in conjuction with typed datasets in .NET. For example, let say we have a query like that:
select id, name, age, rank, hometown from .........;We've created fill/get method that loads all data. Now, when we need to filter for id - we're adding another fill/get method:
select id, name, age, rank, hometown from ..... where id=@id;Then we need to filter by name and hometown - next method:
select id, name, age, rank, hometown from .... where name=@name and hometown=@hometown;Suppose now we need to filter for all other columns and their combinations - we quickly end up creating a mess of similar methods, like method for filtering for name and hometown, rank and age, rank and age and name, etc., etc.
One option is to create suitable query programatically, the other, much simpler, is to use one fill/get method that will provide all filtering possibilites:
select id, name, age, rank, hometown from .....
where
(@id = -1 OR id = @id) AND
(@name = '*' OR name = @name OR (@name is null AND name is null)) AND
(@age = -1 OR age = @age OR (@age is null AND age is null)) AND
(@rank = '*' OR rank = @rank OR (@rank is null AND rank is null) AND
(@hometown = '*' OR hometown = @hometown OR (@hometown is null AND hometown is null);Now we have all possible filterings in one query. Let's say get method name is get_by_filters with signature:
get_by_filters(int id, string name, int? age, string rank, string hometown)Want to filter just by name?:
get_by_filters(-1,"John",-1,"*","*");By age and rank where hometown is null?:
get_by_filters(-1, "*", 23, "some rank", null);etc. etc.
Just one method, one query and all filter combinations. It saved me a lot of time.
One drawback is that you have to "reserve" integer/string for "doesn't matter" filter. But you shouldn't expect an id of value -1 and person with name '*' (of course this is context dependant) so not big problem IMHO.
Edit:
Just to quickly explain the mechanism, let's take a look at first line after where:
(@id = -1 OR id = @id) AND ...When parameter @id is set to -1 the query becomes:
(-1 = -1 OR id = -1) AND ...Thanks to short-circuit boolean logic, the second part of OR is not going to be even tested: -1 = -1 is always true.
If parameter @id was set to, lets sa'y, 77:
(77 = -1 OR id = 77) AND ...then 77 = -1 is obviously false, so test for column id equal 77 will be performed. Same for other parameters. This is really easy yet powerful.
Answer by BoltBait
Never normalize a database to the point that writing a query becomes near impossible.
Example: Concatenating arbitrary number of rows of strings in mysql (hierarchical query)
Answer by Allan Simonsen
Aliasing tables and joining a table with it self multiple times:
select pf1.PageID, pf1.value as FirstName, pf2.value as LastName
from PageFields pf1, PageFields pf2
where pf1.PageID = 42
and pf2.PageID = 42
and pf1.FieldName = 'FirstName'
and pf2.FieldName = 'LastName'Edit: If i have the table PageFields with rows:
id | PageID | FieldName | Value
.. | ... | ... | ...
17 | 42 | LastName | Dent
.. | ... | ... | ...
23 | 42 | FirstName | Arthur
.. | ... | ... | ... Then the above SQL would return:
42, 'Arthur', 'Dent'Answer by Chris Nava
Take advantage of SQL's ability to output not just database data but concatinated text to generate more SQL or even Java code.
-
Generate insert statements
- select 'insert .... values(' + col1 ... + ')' from persontypes
-
Generate the contents of an Enum from a table.
- ...
-
Generate java Classes from table names
- select 'public class ' + name + '{\n}' from sysobjects where...
EDIT: Don't forget that some databases can output XML which saves you lots of time reformatting output for client applications.
Answer by DevinB (Jan 28, 2009)
This doesn't necessarily save you coding time, but this missing indexes query can save you the time of manually figuring out what indexes to create. It is also helpful because it shows actual usage of the indexes, rather than the usage you 'thought' would be common.
http://blogs.msdn.com/bartd/archive/2007/07/19/are-you-using-sql-s-missing-index-dmvs.aspx
Answer by Scorpi0
[Oracle] How to not explode your rollback segment :
delete
from myTable
where c1 = 'yeah';
commit;It could never finish if there is too many data to delete...
create table temp_myTable
as
select *
from myTable
where c1 != 'yeah';
drop myTable;
rename temp_myTable to myTable;Juste recreate index/recompile objects, and you are done !
Answer by le dorfier
Off the top of my head:
Use your editor artistry to make it easy to highlight subsections of a query so you can test them easily in isolation.
Embed test cases in the comments so you can highlight and execute them easily. This is especially handy for stored procedures.
Obviously a really popular technique is getting the folks on Stack Overflow to work out the hard ones for you. :) We SQL freaks are real suckers for pop quizzes.
Answer by jimmyorr (Jan 30, 2009)
Tom Kyte's Oracle implementation of MySQL's group_concat aggregate function to create a comma-delimited list:
with data as
(select job, ename,
row_number () over (partition by job order by ename) rn,
count (*) over (partition by job) cnt
from emp)
select job, ltrim (sys_connect_by_path (ename, ','), ',') scbp
from data
where rn = cnt
start with rn = 1
connect by prior job = job and prior rn = rn - 1
order by jobsee: http://tkyte.blogspot.com/2006/08/evolution.html
Answer by Ralph Lavelle
Using Boolean shortcuts in the filters to avoid what I used to do (with horrible string concatenation before executing the final string) before I knew better. This example is from a search Stored Procedure where the user may or may not enter Customer Firstname and Lastname
@CustomerFirstName VarChar(50) = NULL,
@CustomerLastName VarChar(50) = NULL,
SELECT * (I know, I know)
FROM Customer c
WHERE ((@CustomerFirstName IS NOT NULL AND
c.FirstName = @CustomerFirstName)
OR @CustomerFirstName IS NULL)
AND ((@CustomerLastName IS NOT NULL AND
c.LastName = @CustomerLastName)
OR @CustomerLastName IS NULL)Answer by Rex Miller (Jan 31, 2009)
Not detailed enough and too far down to win the bounty but...
Did anyone already mention UNPIVOT? It lets you normalize data on the fly from:
Client | 2007 Value | 2008 Value | 2009 Value --------------------------------------------- Foo 9000000 10000000 12000000 Bar - 20000000 15000000
To:
Client | Year | Value ------------------------- Foo 2007 9000000 Foo 2008 10000000 Bar 2008 20000000 Foo 2009 12000000 Bar 2009 15000000
And PIVOT, which pretty much does the opposite.
Those are my big ones in the last few weeks. Additionally, reading Jeff's SQL Server Blog is my best overall means of saving time and/or code vis a vis SQL.
Answer by Max Gontar
1. Hierarchical tree formatting SELECT using CTE (MS SQL 2005)
Say you have some table with hierarchical tree structure (departments on example) and you need to output it in CheckBoxList or in Lable this way:
Main Department
Department 1
Department 2
SubDepartment 1
Department 3
Then you can use such query:
WITH Hierarchy(DepartmentID, Name, ParentID, Indent, Type) AS
(
-- First we will take the highest Department (Type = 1)
SELECT DepartmentID, Name, ParentID,
-- We will need this field for correct sorting
Name + CONVERT(VARCHAR(MAX), DepartmentID) AS Indent,
1 AS Type
FROM Departments WHERE Type = 1
UNION ALL
-- Now we will take the other records in recursion
SELECT SubDepartment.DepartmentID, SubDepartment.Name,
SubDepartment.ParentID,
CONVERT(VARCHAR(MAX), Indent) + SubDepartment.Name + CONVERT(VARCHAR(MAX),
SubDepartment.DepartmentID) AS Indent, ParentDepartment.Type + 1
FROM Departments SubDepartment
INNER JOIN Hierarchy ParentDepartment ON
SubDepartment.ParentID = ParentDepartment.DepartmentID
)
-- Final select
SELECT DepartmentID,
-- Now we need to put some spaces (or any other symbols) to make it
-- look-like hierarchy
REPLICATE(' ', Type - 1) + Name AS DepartmentName, ParentID, Indent
FROM Hierarchy
UNION
-- Default value
SELECT -1 AS DepartmentID, 'None' AS DepartmentName, -2, ' ' AS Indent
-- Important to sort by this field to preserve correct Parent-Child hierarchy
ORDER BY Indent ASCOther samples
Using stored procedure: http://vyaskn.tripod.com/hierarchies_in_sql_server_databases.htm
Plain select for limited nesting level: http://www.sqlteam.com/article/more-trees-hierarchies-in-sql
Another one solution using CTE: http://www.sqlusa.com/bestpractices2005/executiveorgchart/
2. Last Date selection with grouping - using RANK() OVER
Imagine some Events table with ID, User, Date and Description columns. You need to select all last Events for each User. There is no guarantee that Event with higher ID has nearest Date.
What you can do is play around with INNER SELECT, MAX, GROUPING like this:
SELECT E.UserName, E.Description, E.Date
FROM Events E
INNER JOIN
(
SELECT UserName, MAX(Date) AS MaxDate FROM Events
GROUP BY UserName
) AS EG ON E.Date = EG.MaxDateBut I prefer use RANK OVER:
SELECT EG.UserName, EG.Description, EG.Date FROM
(
SELECT RANK() OVER(PARTITION BY UserName ORDER BY Date DESC) AS N,
E.UserName, E.Description, E.Date
FROM Events E
) AS EG
WHERE EG.N = 1It's more complicated, but it seems to be more correct for me.
3. Paging using TOP and NOT IN
There is already paging here, but I just can't forget this great experience:
DECLARE @RowNumber INT, @RecordsPerPage INT, @PageNumber INT
SELECT @RecordsPerPage = 6, @PageNumber = 7
SELECT TOP(@RecordsPerPage) * FROM [TableName]
WHERE ID NOT IN
(
SELECT TOP((@PageNumber-1)*@RecordsPerPage) ID
FROM [TableName]
ORDER BY Date ASC
)
ORDER BY Date ASC4. Set variable values in dynamic SQL with REPLACE
Instead of ugly
SET @SELECT_SQL = 'SELECT * FROM [TableName]
WHERE Date < ' + CAST(@Date, VARCHAR) + ' AND Flag = ' + @FlagIt's more easy, safe and readable to use REPLACE:
DECLARE @VAR_SQL VARCHAR(3000), @SELECT_SQL VARCHAR(3000)
DECLARE @Id INT
SET @Id = 3
DECLARE @Flag VARCHAR(1)
SET @Flag = 'X'
DECLARE @Date DATETIME
SET @Date = GETDATE()
SET @VAR_SQL =
'DECLARE @Date DATETIME
SET @Date = CAST(:Date AS DATETIME)
'
SET @SELECT_SQL = 'SELECT * FROM [TableName]
WHERE Id > :Id AND Flag = :Flag AND Date < @Date'
SET @SELECT_SQL =
REPLACE(@SELECT_SQL, ':Flag', QUOTENAME(CONVERT(VARCHAR, @Flag),''''))
SET @SELECT_SQL = REPLACE(@SELECT_SQL, ':Id', CONVERT(VARCHAR, @Id))
SET @VAR_SQL =
REPLACE(@VAR_SQL, ':Date', QUOTENAME(CONVERT(VARCHAR, @Date),''''))
PRINT(@VAR_SQL + @SELECT_SQL)
EXEC(@VAR_SQL + @SELECT_SQL)5. DROP before CREATE
There are some good practices for writing stored procedures or functions, one of them is to include IF EXISTS ... DROP block in procedure creation script.
IF EXISTS
(
SELECT 1 FROM sysobjects
WHERE id = OBJECT_ID(N'[ProcedureName]')
AND OBJECTPROPERTY(id, N'IsProcedure') = 1
)
DROP PROCEDURE [ProcedureName]
GO
IF EXISTS
(
SELECT 1 FROM sysobjects
WHERE id = OBJECT_ID(N'[ScalarFunctionName]')
AND OBJECTPROPERTY(id, N'IsScalarFunction') = 1
)
DROP FUNCTION [ScalarFunctionName]
GO
IF EXISTS
(
SELECT 1 FROM sysobjects
WHERE id = OBJECT_ID(N'[TableFunctionName]')
AND OBJECTPROPERTY(id, N'IsTableFunction') = 1
)
DROP FUNCTION [TableFunctionName]
GOTalking about temporary tables:
IF OBJECT_ID('tempdb..#TEMP') IS NOT NULL
DROP TABLE #TEMP
CREATE TABLE #TEMP(ID INT, DATESTART DATETIME, DATEEND DATETIME)6. Lot of dynamic sql, temp tables, and others on Erland Sommarskog's home page
Answer by Peter Mortensen
SQL's Pivot command (PDF). Learn it. Live it.
Answer by aekeus (Jan 28, 2009)
There are a few things that can be done to minimize the amount of code that needs to be written and insulate you from code changes when the database schema changes (it will).
So, in no particular order:
- DRY up your schema - get it into third normal form
-
DML and Selects can come via views in your client code
- When your underlying tables changes, update the view
- Use INSTEAD OF triggers to intercept DML calls to the view - then update the necessary tables
- Build an external data dictionary containing the structure of your database - build the DDL from the dictionary. When you change database products, write a new parser to build the DDL for your specific server type.
- Use constraints, and check for them in your code. The database that only has one piece of client code interacting with it today, will have two tomorrow (and three the next day).
Answer by Evgeny (Jan 28, 2009)
Using the WITH statement together with ROW_NUMBER function to perform a search and at the same time sort the results by a required field. Consider the following query, for example (it is a part of stored procedure):
DECLARE @SortResults int;
SELECT @SortResults =
CASE @Column WHEN 0 THEN -- sort by Receipt Number
CASE @SortOrder WHEN 1 THEN 0 -- sort Ascending
WHEN 2 THEN 1 -- sort Descending
END
WHEN 1 THEN -- sort by Payer Name
CASE @SortOrder WHEN 1 THEN 2 -- sort Ascending
WHEN 2 THEN 3 -- sort Descending
END
WHEN 2 THEN -- sort by Date/Time paid
CASE @SortOrder WHEN 1 THEN 4 -- sort Ascending
WHEN 2 THEN 5 -- sort Descending
END
WHEN 3 THEN -- sort by Amount
CASE @SortOrder WHEN 1 THEN 4 -- sort Ascending
WHEN 2 THEN 5 -- sort Descending
END
END;
WITH SelectedReceipts AS
(
SELECT TOP (@End) Receipt.*,
CASE @SortResults
WHEN 0 THEN ROW_NUMBER() OVER (ORDER BY Receipt.ReceiptID)
WHEN 1 THEN ROW_NUMBER() OVER (ORDER BY Receipt.ReceiptID DESC)
WHEN 2 THEN ROW_NUMBER() OVER (ORDER BY Receipt.PayerName)
WHEN 3 THEN ROW_NUMBER() OVER (ORDER BY Receipt.PayerName DESC)
WHEN 4 THEN ROW_NUMBER() OVER (ORDER BY Receipt.DatePaid)
WHEN 5 THEN ROW_NUMBER() OVER (ORDER BY Receipt.DatePaid DESC)
WHEN 6 THEN ROW_NUMBER() OVER (ORDER BY Receipt.ReceiptTotal)
WHEN 7 THEN ROW_NUMBER() OVER (ORDER BY Receipt.ReceiptTotal DESC)
END
AS RowNumber
FROM Receipt
WHERE
( Receipt.ReceiptID LIKE ''%'' + @SearchString + ''%'' )
ORDER BY RowNumber
)
SELECT * FROM SelectedReceipts
WHERE RowNumber BETWEEN @Start AND @EndAnswer by pablito
Calculating the product of all rows (x1*x2*x3....xn) in one "simple" query
SELECT exp(sum(log(someField))) FROM Orderstaking advantage of the logarithm properties:
log(x) + log(y) = log(x*y)
exp(log(xy)) = xy
not that I will ever need something like that.......
Answer by geofftnz
Kind of off-topic and subjective, but pick a coding style and stick to it.
It will make your code many times more readable when you have to revisit it. Separate sections of the SQL query into parts. This can make cut-and-paste coding easier because individual clauses are on their own lines. Aligning different parts of join and where clauses makes it easy to see what tables are involved, what their aliases are, what the parameters to the query are...
Before:
select it.ItemTypeName, i.ItemName, count(ti.WTDLTrackedItemID) as ItemCount
from WTDL_ProgrammeOfStudy pos inner join WTDL_StudentUnit su
on su.WTDLProgrammeOfStudyID = pos.WTDLProgrammeOfStudyID inner join
WTDL_StudentUnitAssessment sua on sua.WTDLStudentUnitID = su.WTDLStudentUnitID
inner join WTDL_TrackedItem ti on ti.WTDLStudentUnitAssessmentID = sua.WTDLStudentUnitAssessmentID
inner join WTDL_UnitItem ui on ti.WTDLUnitItemID = ui.WTDLUnitItemID inner
join WTDL_Item i on ui.WTDLItemID = i.WTDLItemID inner join WTDL_ItemType it
on i.WTDLItemTypeID = it.WTDLItemTypeID where it.ItemTypeCode = 'W' and i.ItemName like 'A%'
group by it.ItemTypeName, i.ItemName order by it.ItemTypeName, i.ItemNameAfter:
select it.ItemTypeName,
i.ItemName,
count(ti.WTDLTrackedItemID) as ItemCount
from WTDL_ProgrammeOfStudy pos
inner join WTDL_StudentUnit su on su.WTDLProgrammeOfStudyID = pos.WTDLProgrammeOfStudyID
inner join WTDL_StudentUnitAssessment sua on sua.WTDLStudentUnitID = su.WTDLStudentUnitID
inner join WTDL_TrackedItem ti on ti.WTDLStudentUnitAssessmentID = sua.WTDLStudentUnitAssessmentID
inner join WTDL_UnitItem ui on ti.WTDLUnitItemID = ui.WTDLUnitItemID
inner join WTDL_Item i on ui.WTDLItemID = i.WTDLItemID
inner join WTDL_ItemType it on i.WTDLItemTypeID = it.WTDLItemTypeID
where it.ItemTypeCode = 'W'
and i.ItemName like 'A%'
group by it.ItemTypeName,
i.ItemName
order by it.ItemTypeName,
i.ItemNameAnswer by user59861 (Jan 28, 2009)
Three words... UPDATE FROM WHERE
Answer by GregD
That would be
copy & pasteBut in all seriousness, I've gotten in the habit of formatting my code so that lines are much easier to comment out. For instance, I drop all new lines down from their SQL commands and put the comma's at the end instead of where I used to put them (at the beginning). So my code ends up looking like this
Select
a.deposit_no,
a.amount
From
dbo.bank_tran a
Where
a.tran_id = '123'Oh and ALIASING!
Answer by jimmyorr
Analytic functions like rank, dense_rank, or row_number to provide complex ranking.
The following example gives employees a rank in their deptno, based on their salary
and hiredate (highest paid, oldest employees):
select e.*,
rank() over (
partition by deptno
order by sal desc, hiredate asc
) rank
from emp eAnswer by Cape Cod Gunny
I wrote a stored procedure called spGenerateUpdateCode. You passed it a tablename or viewname and it generated an entire T-SQL Stored Procedure for updating that table. All I had to do was copy and paste into TextPad (my favorite editor). Do some minor find and replaces and minimal tweaking and BAM... update done.
I would create special views of base tables and call spGenerateUpdateCode when I needed to do a partial updates.
That single 6 hour coding session saved me hundreds of hours.
This proc created two blocks of code. One for inserts and one for updates.
Answer by AJ.
I offer these suggestions, which have helped me:
Stored procedures and views
Use stored procedures to encapsulate complex joins over many tables - both for selects and for updates/inserts. You can also use views where the joins don't involve too many tables. (where "too many" is a vague quantity between 4 and 10).
So, for example, if you want information on a customer, and it's spread over lots of tables, like "customer", "address", "customer status code", "order", "invoice", etc., you could create a stored procedure called "getCustomerFullDetail" which joins all those tables, and your client code can just call that and never have to worry about the table structure.
For updates, you can create "updateCustomerFullDetail", which could apply updates sensibly.
There will be some performance hits for this, and writing the stored procedures might be non-trivial, but you're writing the non-trivial code once, in SQL (which is typically succinct).
Normalisation
Normalise your database.
Really.
This results in cleaner (simpler) update code which is easier to maintain.
It may have other benefits which are not in scope here.
I normalise to at least 4NF.
4NF is useful because in includes making all your lists of possible values explicit, so your code doesn't have to know about, e.g. all possible status codes, so you don't hard-code lists in client code.
(3NF is the one which really sorts out those update anomalies.)
Perhaps use an ORM?
This is as much a question as a suggestion: would a good ORM reduce the amount of code you have to write? Or does it just remove some of the pain from moving data from the database to the client? I haven't played with one enough.
Answer by rp.
Learn T4!
It's a great little tool to have around. Creating templates is a little work at first, but not hard at all once you get the hang of it. I know that in the age of ORMs, the example below is perhaps dated, but you'll get the idea.
See these links for more on T4:
Start here:
Others of interest:
- Code Generation and T4 Text Templates
- Microsoft's T4: A Free Alternative to CodeSmith
- T4 Editor, an editor from Clarius
The T4 template
<#@ template language="C#" #>
<#@ output extension="CS" #>
<#@ assembly name="Microsoft.SqlServer.ConnectionInfo" #>
<#@ assembly name="Microsoft.SqlServer.Smo" #>
<#@ import namespace="Microsoft.SqlServer.Management.Smo" #>
<#@ import namespace="System.Collections.Specialized" #>
<#@ import namespace="System.Text" #>
<#
Server server = new Server( @"DUFF\SQLEXPRESS" );
Database database = new Database( server, "Desolate" );
Table table = new Table( database, "ConfirmDetail" );
table.Refresh();
WriteInsertSql( table );
#>
<#+
private void WriteInsertSql( Table table )
{
PushIndent( " " );
WriteLine( "const string INSERT_SQL = " );
PushIndent( " " );
WriteLine( "@\"INSERT INTO " + table.Name + "( " );
PushIndent( " " );
int count = 0;
// Table columns.
foreach ( Column column in table.Columns )
{
count++;
Write( column.Name );
if ( count < table.Columns.Count ) Write( ",\r\n" );
}
WriteLine( " )" );
PopIndent();
WriteLine( "values (" );
PushIndent( " " );
count = 0;
// Table columns.
foreach ( Column column in table.Columns )
{
count++;
Write( "@" + column.Name );
if ( count < table.Columns.Count ) Write( ",\r\n" );
}
WriteLine( " )\";" );
PopIndent();
PopIndent();
PopIndent();
WriteLine( "" );
}
#>outputs this for any table specfied:
const string INSERT_SQL =
@"INSERT INTO ConfirmDetail(
ConfirmNumber,
LineNumber,
Quantity,
UPC,
Sell,
Description,
Pack,
Size,
CustomerNumber,
Weight,
Ncp,
DelCode,
RecordID )
values (
@ConfirmNumber,
@LineNumber,
@Quantity,
@UPC,
@Sell,
@Description,
@Pack,
@Size,
@CustomerNumber,
@Weight,
@Ncp,
@DelCode,
@RecordID )";Answer by Paul W Homer (Jan 28, 2009)
Way back, I wrote dynamic SQL in a C program that took a table as an argument. It would then access the database (Ingres in those days) to check the structure, and using a WHERE clause, load any matching row into a dynamic hash/array table.
From there, I would just lookup the indices to the values as I used them. It was pretty slick, and there was no other SQL code in the source (also it had a feature to be able to load a table directly into a tree).
The code was a bit slower than brute force, but it optimized the overall program because I could quickly do partitioning of the data in the code, instead of in the database.
Paul.
Answer by inspite (Jan 28, 2009)
Make sure you know what SELECT can do.
I used to spend hours writing dumb queries that SQL does out of the box (eg NOT IN and HAVING spring to mind)
Answer by Garry Shutler
What I call the sum case construct. It's a conditional count. A decent example of it is this answer to a question.
Answer by Barry (Feb 05, 2009)
De-dup a table fast and easy. This SQL is Oracle-specific, but can be modified as needed for whatever DB you are using:
DELETE table1 WHERE rowid NOT IN (SELECT MAX(rowid) FROM table1 GROUP BY dup_field)
Answer by Allethrin (Jan 29, 2009)
Derived tables. Example below is simple (and makes more sense as a join), but in more complex cases they can be very handy. Using these means you don't have to insert a temporary result set into a table just to use it in a query.
SELECT tab1.value1,
tab2.value1
FROM mytable tab1,
( SELECT id,
value1 = somevalue
FROM anothertable
WHERE id2 = 1234 ) tab2
WHERE tab1.id = tab2.idAnswer by Eric Johnson
Sqsh (pronounced skwish) is short for SQshelL (pronounced s-q-shell), it is intended as a replacement for the venerable 'isql' program supplied by Sybase. It came about due to years of frustration of trying to do real work with a program that was never meant to perform real work.
My favorite feature is that it contains a (somewhat feeble) scripting language which allows a user to source handy functions like this from a .sqshrc config file:
\func -x droptablelike
select name from sysobjects where name like "${1}" and type = 'U'
\do
\echo dropping #1
drop table #1
go
\done
\doneAnswer by Bill Karwin (Jan 30, 2009)
Generating SQL to update one table based on the contents of another table.
Some database brands such as MySQL and Microsoft SQL Server support multi-table UPDATE syntax, but this is non-standard SQL and as a result each vendor implements different syntax.
So to make this operation more portable, or when we had to do it years ago before the feature existed in any SQL implementation, you could use this technique.
Say for example you have employees and departments. You keep a count of employees per department as an integer in the departments table (yes this is denormalized, but assume for the moment that it's an important optimization).
As you change the employees of a department through hiring, firing, and transfers, you need to update the count of employees per department. Suppose you don't want to or can't use subqueries.
SELECT 'UPDATE departments SET emp_count = ' || COUNT(e.emp_id)
|| ' WHERE dept_id = ' || e.dept_id || ';'
FROM employees e
GROUP BY e.dept_id;The capture the output, which is a collection of SQL UPDATE statements. Run this as an SQL script.
It doesn't have to be a query using GROUP BY, that's just one example.
Answer by mjy (Jan 30, 2009)
The nested set method for storing trees / hierarchical data, as explained in Joe Celko's famous book ("SQL for smarties") and also e.g. here (too long to post here).
Answer by user29439 (Jan 30, 2009)
You simply must love the Tally table approach to looping. No WHILE or CURSOR loops needed. Just build a table and use a join for iterative processing. I use it primarily for parsing data or splitting comma-delimited strings.
This approach saves on both typing and performance.
From Jeff's post, here are some code samples:
--Build the tally table:
IF OBJECT_ID('dbo.Tally') IS NOT NULL
DROP TABLE dbo.Tally
SELECT TOP 10000 IDENTITY(INT,1,1) AS N
INTO dbo.Tally
FROM Master.dbo.SysColumns sc1,
Master.dbo.SysColumns sc2
ALTER TABLE dbo.Tally
ADD CONSTRAINT PK_Tally_N
PRIMARY KEY CLUSTERED (N) WITH FILLFACTOR = 100
--Split a CSV column
--Build a table with a CSV column.
CREATE TABLE #Demo (
PK INT IDENTITY(1,1) PRIMARY KEY CLUSTERED,
CsvColumn VARCHAR(500)
)
INSERT INTO #MyHead
SELECT '1,5,3,7,8,2'
UNION ALL SELECT '7,2,3,7,1,2,2'
UNION ALL SELECT '4,7,5'
UNION ALL SELECT '1'
UNION ALL SELECT '5'
UNION ALL SELECT '2,6'
UNION ALL SELECT '1,2,3,4,55,6'
SELECT mh.PK,
SUBSTRING(','+mh.CsvColumn+',',N+1,CHARINDEX(',',','+mh.CsvColumn+',',N+1)-N-1) AS Value
FROM dbo.Tally t
CROSS JOIN #MyHead mh
WHERE N < LEN(','+mh.CsvColumn+',')
AND SUBSTRING (','+mh.CsvColumn+',',N,1) = ','Answer by Timur Fanshteyn (Jan 31, 2009)
Use Excel to generate SQL Queries. This works great when you need to insert, update, delete rows based on a CSV that was provided to you. All you have to do is create the right CONCAT() formula, and then drag it down to create the SQL Script
Answer by Bernard Dy (Feb 03, 2009)
The SQL MERGE command:
In the past developers had to write code to handle situations where in one condition the database does an INSERT but in others (like when the key already exists) they do an UPDATE.
Now databases support the "upsert" operation in SQL, which will take care of some of that logic for you in a more concise fashion. Oracle and SQL Server both call it MERGE. The SQL Server 2008 version is pretty powerful; I think it can also be configured to handle some DELETE operations.
Answer by SAMills (Feb 03, 2009)
It's not specifically a coding trick but indeed a very helpful (and missing) aid to SQL Server Management Studio:
SQL Prompt - Intelligent code completion and layout for MS SQL Server
There are many answers already provided where the outcome was having written snippets in the past that eliminate the need to write the same in the future. I believe Code Completion through intellisense definitely falls into this category. It allows me to concentrate on the logic without worrying so much about the syntax of T-SQL or the schema of the database/table/...
Answer by Quassnoi
Using Oracle hints for a select last effective date query.
For instance, exchange rates for a currenсy change several times a day and there is no regularity in it. Efficient rate for a given moment is the rate published last, but before that moment.
You need to select efficient exchange rate for each transaction from a table:
CREATE TABLE transactions (xid NUMBER, xsum FLOAT, xdate DATE, xcurrency NUMBER);
CREATE TABLE rates (rcurrency NUMBER, rdate DATE, rrate FLOAT);
CREATE UNIQUE INDEX ux_rate_currency_date ON rates (rcurrency, rdate);
SELECT (
SELECT /*+ INDEX_DESC (r ux_rate_currency_date) */
rrate
FROM rates r
WHERE r.rcurrency = x.xcurrency
AND r.rdate <= x.xdate
AND rownum = 1
) AS eff_rate, xsum, date
FROM transactions xThis is not recommended by Oracle, as you rely on index to enforce SELECT order.
But you cannot pass an argument to a double-nested subquery, and have to do this trick.
P.S. It actually works in a production database.
Answer by Colin Pickard (Feb 17, 2009)
SQL Hacks http://oreilly.com/catalog/covers/0596527993_cat.gif SQL Hacks lives on my desk. It is a compendium of useful SQL tricks.
Answer by Christopher Klein (Mar 20, 2009)
Nice quick little utility script I use for when I need to find an ANYTHING in a SQL object (works on MSSQL 2000 and beyond). Just change the @TEXT
SET NOCOUNT ON
DECLARE @TEXT VARCHAR(250)
DECLARE @SQL VARCHAR(250)
SELECT @TEXT='WhatDoIWantToFind'
CREATE TABLE #results (db VARCHAR(64), objectname VARCHAR(100),xtype VARCHAR(10), definition TEXT)
SELECT @TEXT as 'Search String'
DECLARE #databases CURSOR FOR SELECT NAME FROM master..sysdatabases where dbid>4
DECLARE @c_dbname varchar(64)
OPEN #databases
FETCH #databases INTO @c_dbname
WHILE @@FETCH_STATUS -1
BEGIN
SELECT @SQL = 'INSERT INTO #results '
SELECT @SQL = @SQL + 'SELECT ''' + @c_dbname + ''' AS db, o.name,o.xtype,m.definition '
SELECT @SQL = @SQL + ' FROM '+@c_dbname+'.sys.sql_modules m '
SELECT @SQL = @SQL + ' INNER JOIN '+@c_dbname+'..sysobjects o ON m.object_id=o.id'
SELECT @SQL = @SQL + ' WHERE [definition] LIKE ''%'+@TEXT+'%'''
EXEC(@SQL)
FETCH #databases INTO @c_dbname
END
CLOSE #databases
DEALLOCATE #databases
SELECT * FROM #results order by db, xtype, objectname
DROP TABLE #results
The next one is referred to as an UPSERT. I think in MSSQL 2008 you can use a MERGE command but before that if you had to do something in two parts. So your application sends data back to a stored procedure but you dont necessarily know if you should be updating existing data or inserting NEW data. This does both depending:
DECLARE @Updated TABLE (CodeIdentifier VARCHAR(10))
UPDATE AdminOverride
SET Type1='CMBS'
OUTPUT inserted.CodeIdentifier INTO @Updated
FROM AdminOverride a
INNER JOIN ItemTypeSecurity b
ON a.CodeIdentifier = b.CodeIdentifier
INSERT INTO AdminOverride
SELECT c.CodeIdentifier
,Rating=NULL
,Key=NULL
,IndustryType=NULL
,ProductGroup=NULL
,Type1='CMBS'
,Type2=NULL
,SubSectorDescription=NULL
,WorkoutDate=NULL
,Notes=NULL
,EffectiveMaturity=NULL
,CreatedDate=GETDATE()
,CreatedBy=SUSER_NAME()
,ModifiedDate=NULL
,ModifiedBy=NULL
FROM dbo.ItemTypeSecurity c
LEFT JOIN @Updated u
ON c.CodeIdentifier = u.CodeIdentifier
WHERE u.CodeIdentifier IS NULL
If it existed, it updated AND created a record in the @Updated table what it updated, the Insert command only happens for records that are NOT in the @Updated.
Answer by ob.
Using variables in the SQL where clause to cut down on conditional logic in your code/database. You can compare your variable's value against some default (0 for int, let's say), and filter only if they're not equal. For example:
SELECT * FROM table AS t
WHERE (@ID = 0 OR t.id = @ID);If @ID is 0 I'll get back all rows in the table, otherwise it'll filter my results by id.
This technique often comes in handy, especially in search, where you can filter by any number of fields.
Answer by Jean-Francois
If you use MySQL, use Common MySQL Queries.
It really shows a lot of queries that let the database do the job instead of coding multiple queries and doing routine on the result.
Answer by adolf garlic
Red Gate Software's SQL Prompt is very useful.
It has auto completion, code tidy-up, table/stored procedure/view definitions as popup windows, datatype tooltips, etc.
Answer by Frederik
I have had great use of Itzik Ben-Gan's table-valued function fn_nums. It is used to generate a table with a fixed number of integers. Perfect when you need to cross apply a specific number of rows with a single row.
CREATE FUNCTION [dbo].[fn_nums](@max AS BIGINT)RETURNS @retTabl TABLE (rNum INT)
AS
BEGIN
IF ISNULL(@max,0)<1 SET @max=1;
WITH
L0 AS (SELECT 0 AS c UNION ALL SELECT 0),
L1 AS (SELECT 0 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 0 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 0 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 0 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 0 AS c FROM L4 AS A CROSS JOIN L4 AS B)
insert into @retTabl(rNum)
SELECT TOP(@max) ROW_NUMBER() OVER(ORDER BY (SELECT 0)) AS n
FROM L5;
RETURN
ENDAnswer by crosenblum
Information schema, pure and simple.
I just had to write a small application to delete all data with tables or columns named x or y.
Then I looped that in ColdFusion and created what would have taken 20-30 lines in five lines.
It purely rocks.
Answer by jimmyorr
Combining aggregates with case statements (here with a pivot!):
select job,
sum(case when deptno = 10 then 1 end) dept10,
sum(case when deptno = 20 then 1 end) dept20,
sum(case when deptno = 30 then 1 end) dept30
from emp
group by jobShared with attribution, where reasonably possible, per the SO attribution policy and cc-by-something. If you were the author of something I posted here, and want that portion removed, just let me know.